GANs consistently achieve state of the art performance in image generation by learning the distribution of an image corpus.
The newest models often use explicit mechanisms to learn factored representations for images which can be help provide faceted image retrieval, capable of conditioning output on key attributes.
In this post, we explore applying StyleGAN2 embeddings in image retrieval tasks.
StyleGAN2
To begin, we train a StyleGAN2 model to generate theatrical posters from our image corpus.
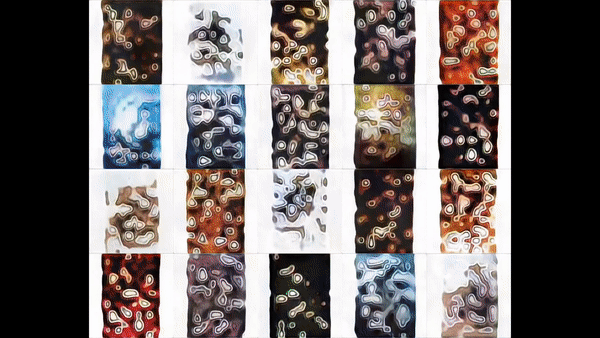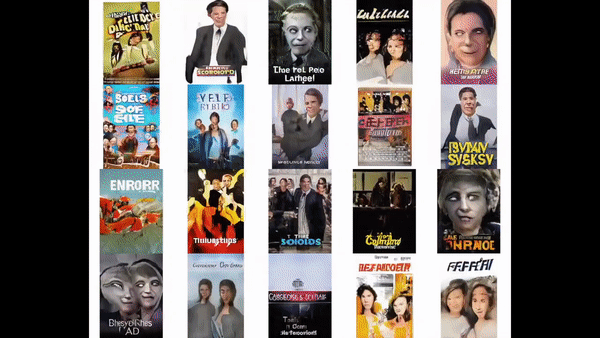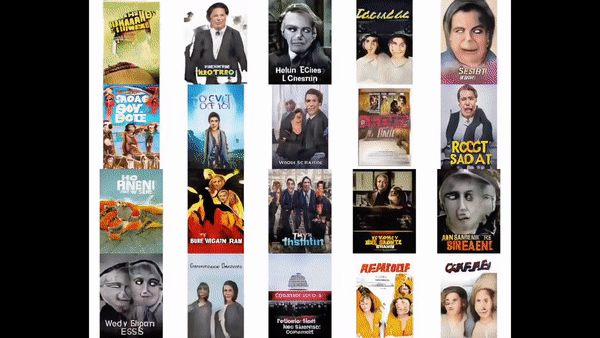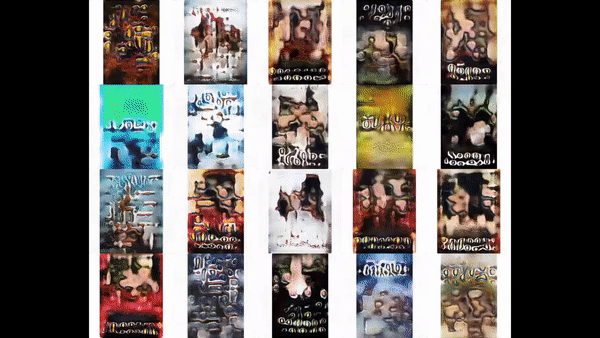
After training the model for 3 weeks on nearly a million images, we finally begin to observe plausible posters.

See a sample realistic enough to fool Google Image search.
A trained StyleGAN2 model can even mix styles between sample images, crossing color palette and textures.

As a byproduct of training our generative model, we obtain methods to produce latent factor representations for each training sample.
Here, we see that StyleGAN2 learns an embedding for each training sample which has some of the characteristics we look for to apply in the image retrieval task.
This approach has the added advantage of not requiring labels to train a model. Despite this, training and generating latent factors was costly! Even if we consider this cost amoritized over an application’s lifecycle, these models are prone to mode collapse and thus poor embeddings.
StyleGAN2-ADA
A recent update to StyleGAN2 uses an adaptive test-time image augmentation scheme to stabilize training with fewer samples. Importantly, this is done in such a way that augmentations do not leak into the generated samples.
This variant can reach similar results to the original StyleGAN2 model with an order of magnitude fewer images in a shorter amount of time. It is also possible to train a new model from a checkpoint generated from the original StyleGAN2 architecture.
Besides requiring fewer images, this model allows for class-conditional training, meaning we can introduce genre labels for additional context.
After fine-tuning from our previous checkpoint file on our image corpus for one day, our generated posters look promising.

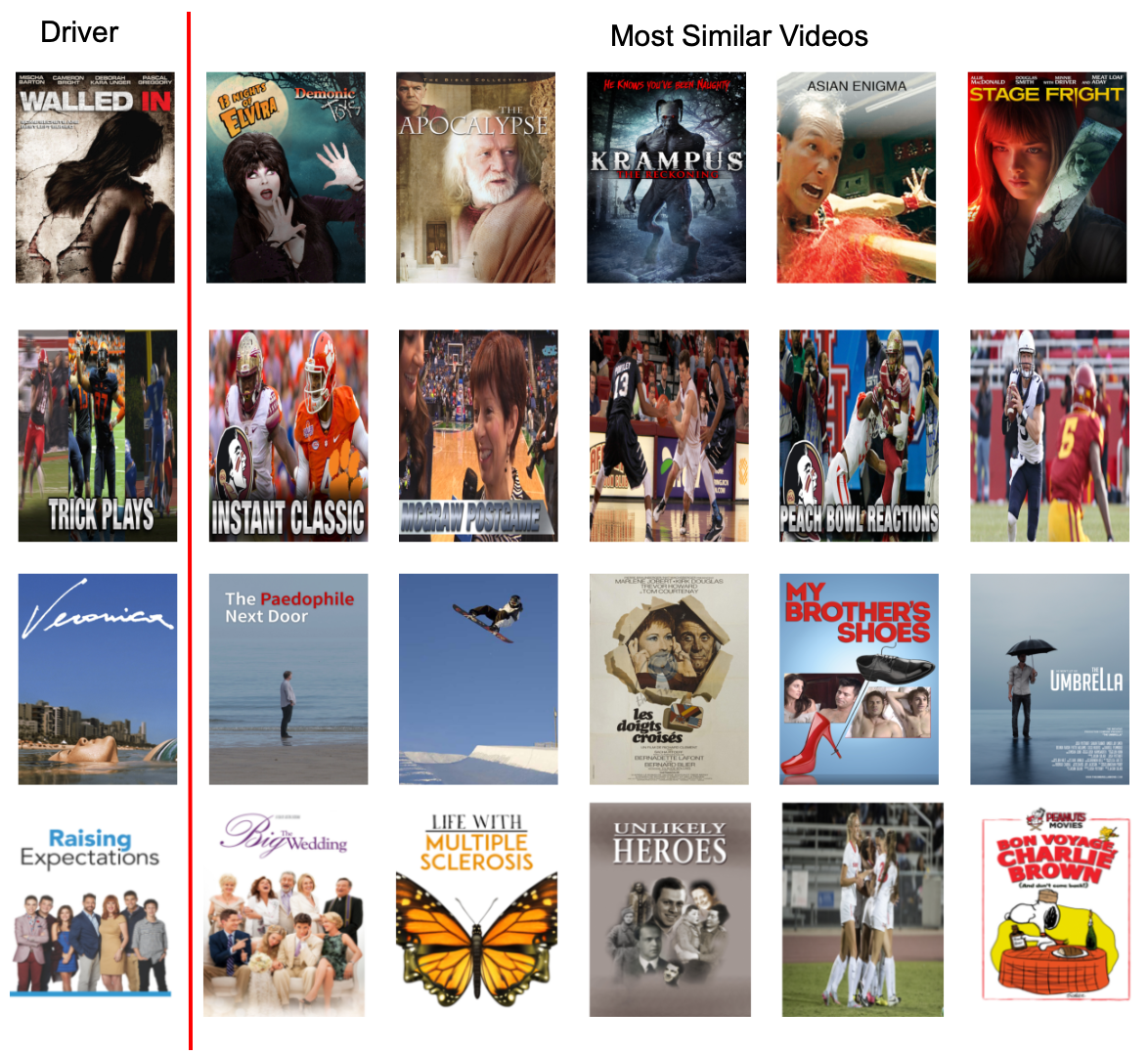
Comparing the most similar posters for a handful of random sample posters, we can see that this new model can capture semantic, color, and texture features like its predecessor in a fraction of the time.

Conclusion
StyleGAN latent factors can effectively capture visual similarity in posters. However, based on some manual review, we consider the metric learning embeddings to be more semantically cohesive. If an overfit discriminator is the bottleneck for improving the GAN performance, we might consider augmenting the image dataset with additional secondary genre labels.
Overall, this method could be useful where labels are sparse or non-existent for a large image corpus and the recent developments with StyleGAN2 in particular make this approach more tractable. Also, the use of the FID-score provides some helpful proxy for comparing training runs which may also guide metric learning evaluations.