Check out this part 1 notebook and this part 2 notebook and part 3 notebook which accompany this post!
Streaming video is quickly occupying the lion’s share of digital content consumed by users of many applications. At the same time more users are streaming from mobile devices, screen sizes are also increasing while consumers expect high-quality video without lag or distortion artifacts. This frames an engineering challenge to optimize the way video is streamed for consumers across a multitude of hardware platforms.
Video streaming sites typically employ adaptive bitrate encoding, whereby video is chunked into groups of pictures (GOPs) and encoded at various bitrate-resolution combinations, allowing client devices to switch dynamically to accommodate changing network conditions.
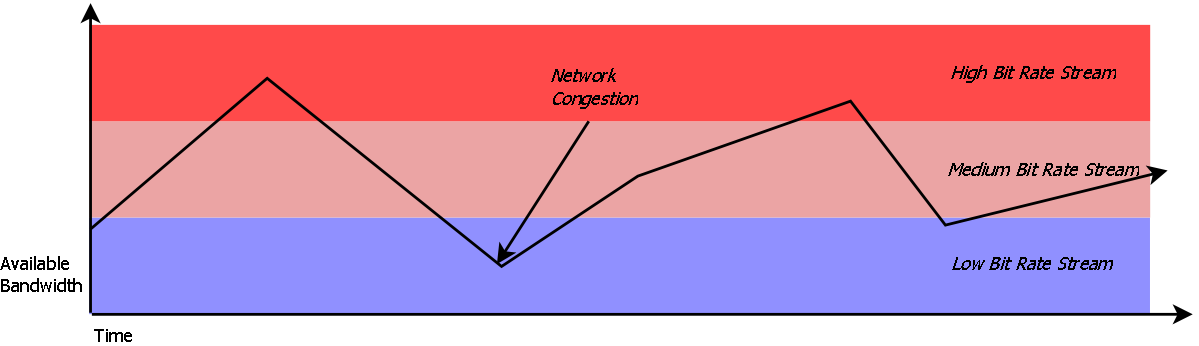
The perceived quality of streaming video can vary depending on bitrate and resolution. To minimize distortion, we seek the video encoding which optimizes for perceived quality.
Generally, we measure signal distortion using PSNR with respect to a reference but metrics like SSIM, MOS and VMAF are also popular choices for video.
Improved streaming experience is core to experience for Netflix users and their engineers found that encodings can be specialized to each title. Using shot detection, they make additional chunk-level optimizations.
For content which will be streamed by many users, the extra work can be justified by tremendous impact!
Taking this further, researchers found additional gains using content-aware encodings. For example, simple animated images are easy to compress compared to fast-motion & spatially complex video sequences.

Groups like Facebook and Twitter have also employed these kinds of optimizations to scale streaming services to mobile users more efficiently.
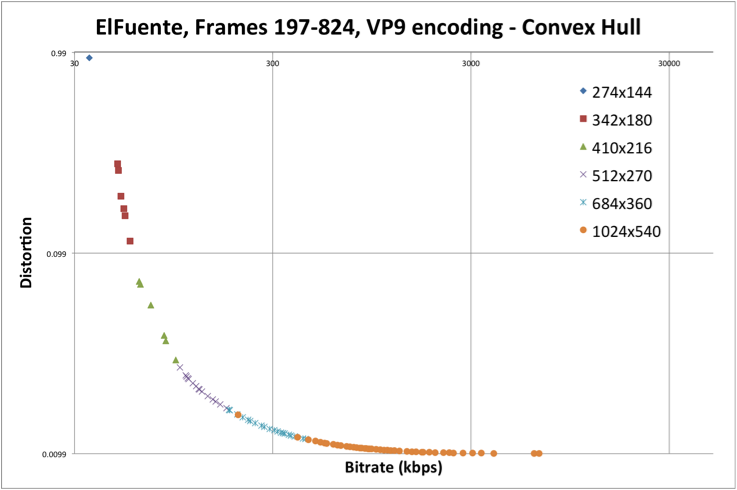
However, encoding video at various bitrate/resolution combinations to compute VMAF against a reference video is computationally very expensive. Additionally, convex hull optimization is required to determine find the best bitrate ladder.
With a naive grid search, we find many encoding combinations are well-below the pareto front. Therefore, recent work focuses on probing more efficiently rather than performing an exhaustive search.
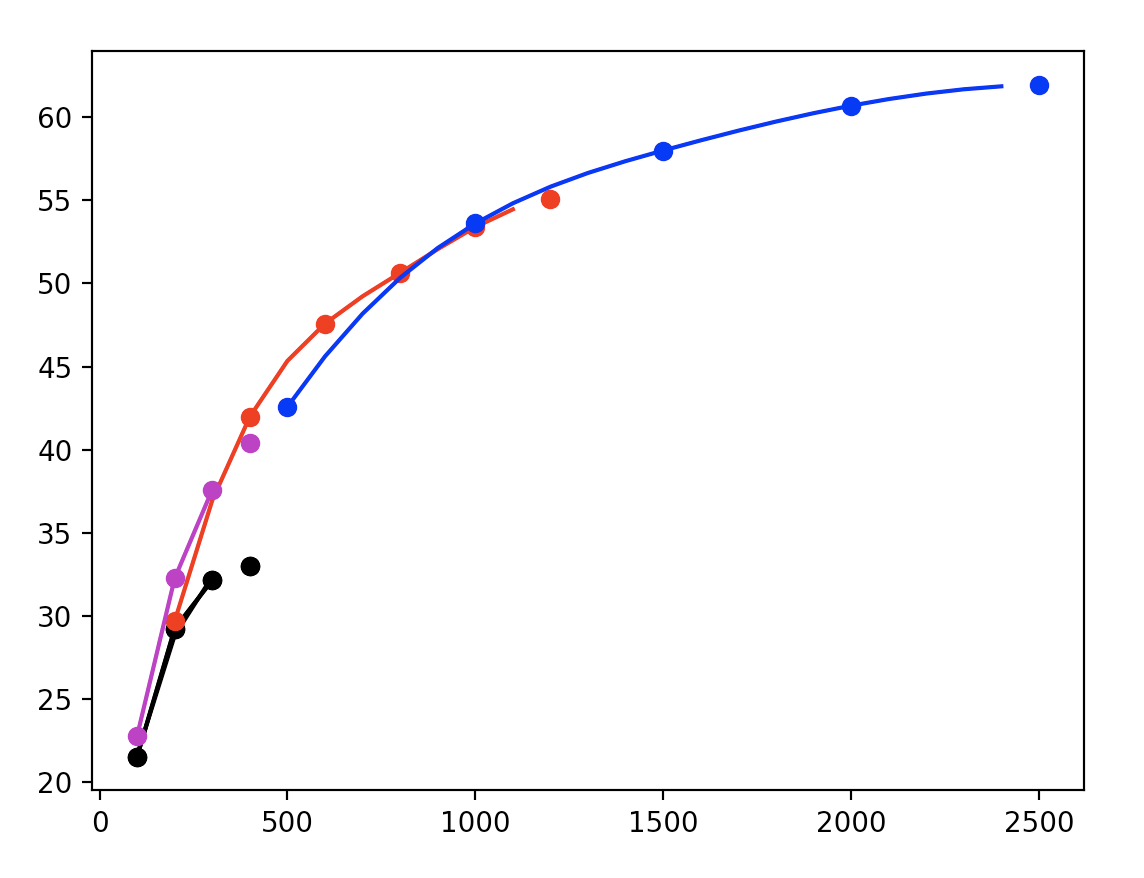
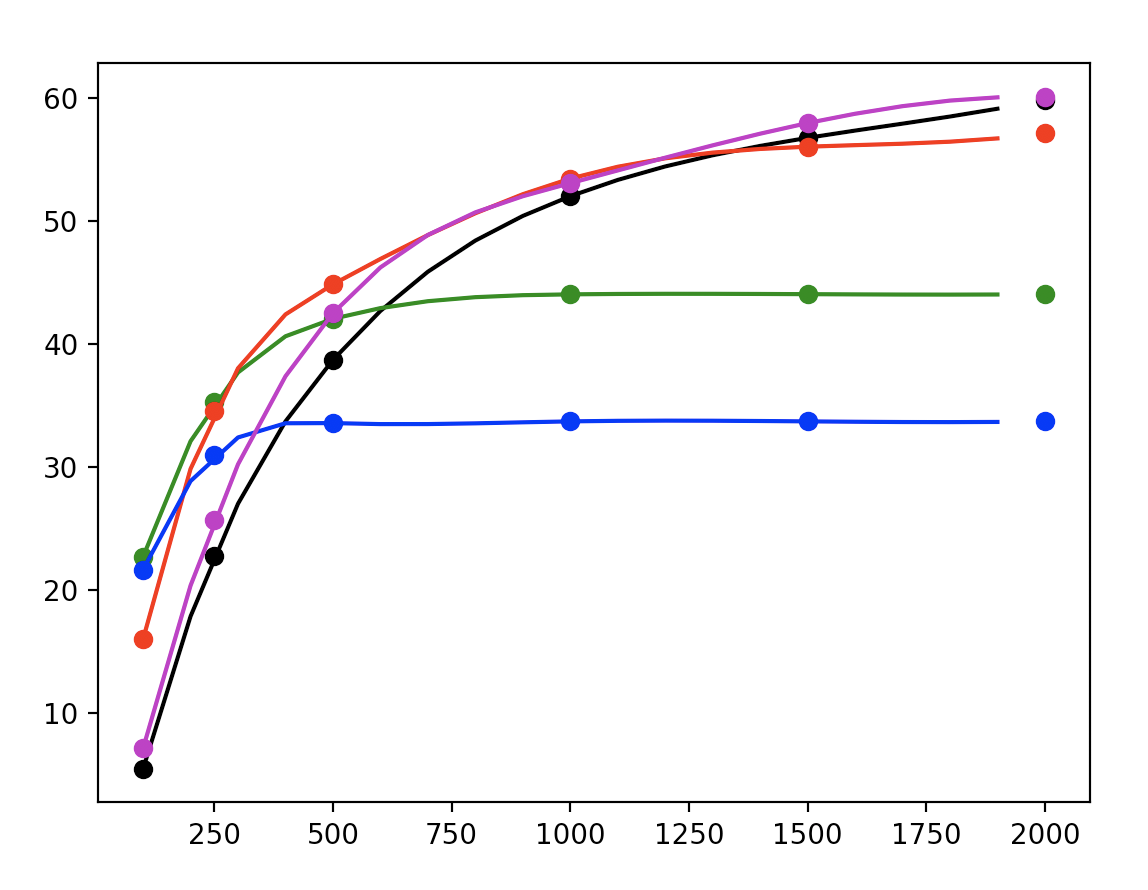
But, without a priori knowledge of video content, it’s difficult to guess the optimal bitrate for each resolution. Instead, we need to extrapolate effectively.
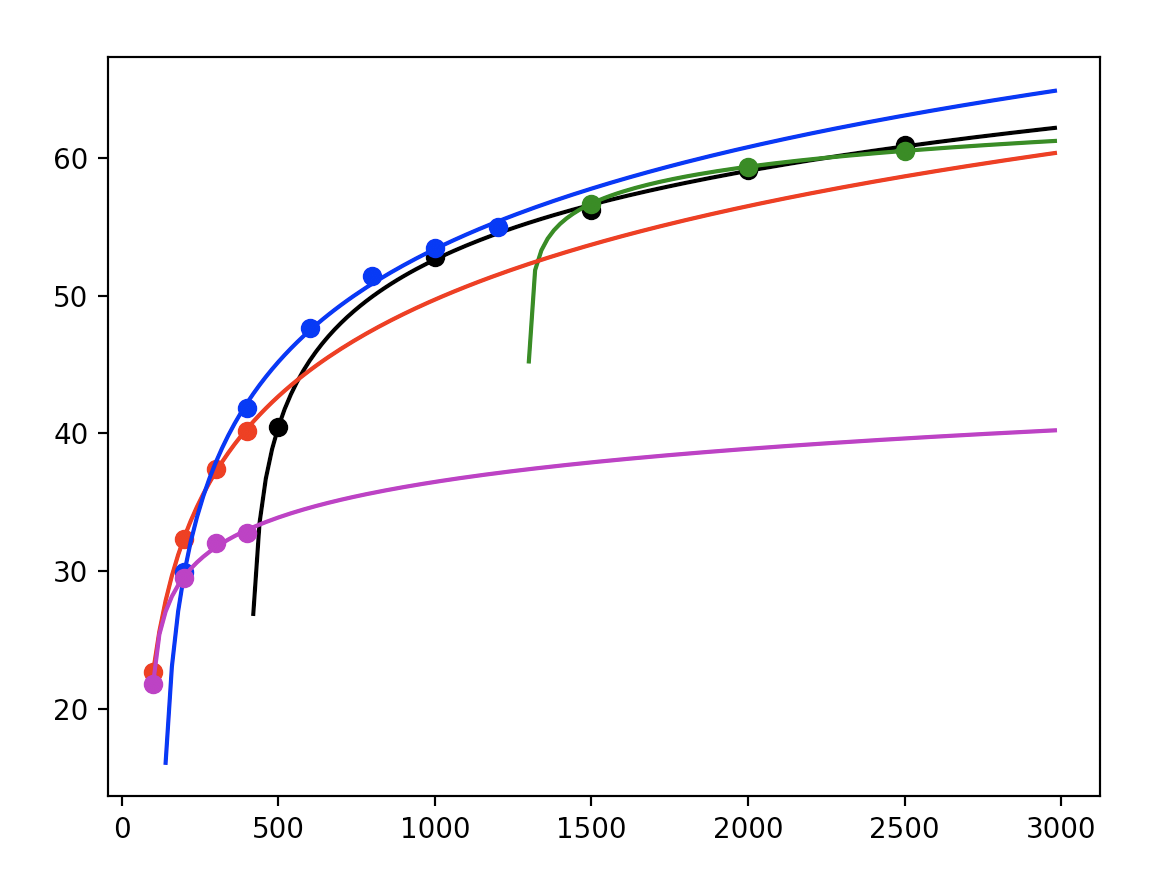
Generally, these rate-distortion curves exhibit logarithmic decay, so we choose to fit a curve of the form:
$$ \begin{equation} f(x | a, b, c) = a \log(x + b) + c \end{equation} $$
by learning parameters a, b, and c.
In this way, we reduce the computational burden with interpolation.
Our databricks notebook shows how Spark + FFmpeg can be used to optimize the bitrate ladder of a sample 4K video.
We can compute these statistics at the shot-level after segmenting our video with a udf like:
shots_schema = ArrayType(
StructType([
StructField("start", FloatType(), False),
StructField("end", FloatType(), False)
]))
@udf(returnType=shots_schema)
def shot_detection(uri, threshold=0.3):
"""
FFmpeg filters threshold sum of absolute differences
in video frames to perform shot detection.
"""
p = subprocess.Popen(
(
ffmpeg.input(uri)
.filter("select", "gte(scene,{})".format(threshold))
.filter("showinfo")
.output("-", format="null")
.compile()
),
stderr=subprocess.PIPE,
)
result = p.communicate()[1].decode("utf-8")
shots = [ln.split()[0] for ln in result.split("pts_time:")]
shots[0] = '0'
shots = np.array(shots, dtype=float).tolist()
shots = list(zip(shots[:-1], shots[1:]))
return shots if shots else [(0, -1)]
Next, our custom udf computes VMAF scores using FFmpeg. Spark helps to distribute our function over a grid of bitrates and resolutions to measure distortion with VMAF.
@udf(returnType=T.DoubleType())
def rate_distortion(video, bitrate, resolution):
width, height = map(int, resolution.split(":"))
cmd = '/home/ubuntu/ffmpeg/ffmpeg -i {} -vf scale={}:{} -c:v libx264 -tune psnr
-x264-params vbv-maxrate={}:vbv-bufsize={} -f rawvideo -f rawvideo pipe: |
/home/ubuntu/ffmpeg/ffmpeg -i pipe: -i {} -filter_complex
"[0:v]scale=1920x1080:flags=bicubic[main]; [1:v]scale=1920x1080:flags=bicubic,format=pix_fmts=yuv420p,fps=fps=30/1[ref];
[main][ref]libvmaf=psnr=true:log_path=vmaflog.json:log_fmt=json" -f null - '.format(
video, width, height, bitrate, bitrate, video
)
ps = subprocess.Popen(
cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT
)
output = ps.communicate()[0]
vmaf = float(str(output).split("VMAF score: ")[-1].split('\\n"')[0])
return vmaf
Using curve-fitting, we can determine the rate-distortion curves for various bitrate-resolution combinations.
@udf(returnType=T.ArrayType(T.FloatType()))
def fit_rd_curve(bitrates, vmafs):
bitrates, vmafs = np.array(bitrates), np.array(vmafs)
log_fit = lambda x, a, b, c: a * np.log(x + b) + c
popt, pcov = curve_fit(log_fit, bitrates, vmafs, maxfev=5000)
return list(map(float, popt))
Now, we can determine the shot-level optimal bitrate ladder by considering the pareto frontier for our computations.
But researchers made another observation: the point of greatest curvature in the rate-distortion curves for high-resolution encodings is often lying on the pareto frontier. Using this, researchers aim to regress this “knee-point” to further reduce computations.
In our model, we compute the second derivative of the rate-distortion curve to obtain the knee-point:
$$ \frac{d^2}{{dx}^2} \left( a * \log(x + b) + c\right) = \frac{-a}{(x + b)^2} $$
After computing these values for many video samples, researchers regress this distinguished value from content signals including spatial and motion features. In this way, informative content-based priors can be used to reduce the workload in optimizing the bitrate ladder for percieved quality.
The following udf, helps to extract image byte arrays for inference:
@udf(returnType=ArrayType(BinaryType()))
def video2images(uri, width, height,
sample_rate: int = 1,
start: float = 0.0,
end: float = -1.0,
n_channels: int = 3):
"""
Uses FFmpeg filters to extract image byte arrays
and sampled & localized to a segment of video in time.
"""
video_data, _ = (
ffmpeg.input(uri, threads=1)
.output(
"pipe:",
format="rawvideo",
pix_fmt="rgb24",
ss=start,
t=end - start,
r=1 / sample_rate,
).run(capture_stdout=True))
img_size = height * width * n_channels
return [video_data[idx:idx + img_size] for idx in range(0, len(video_data), img_size)]
We can obtain image representations for our regressor using a ResNet pretrained on Imagenet.
model = ResNet50(include_top=False)
bc_model_weights = sc.broadcast(model.get_weights())
def model_fn():
model = ResNet50(weights=None, include_top=False)
model.set_weights(bc_model_weights.value)
return model
def preprocess(content):
img = tf.io.decode_png(content, 3)
arr = tf.image.resize(img, [224,224], method='nearest')
return preprocess_input(arr)
def featurize_series(model, content_series):
input = np.stack(content_series.map(preprocess))
preds = model.predict(input)
output = [p.flatten() for p in preds]
return pd.Series(output)
@pandas_udf('array<float>', PandasUDFType.SCALAR_ITER)
def featurize_udf(content_series_iter):
model = model_fn()
for content_series in content_series_iter:
yield featurize_series(model, content_series)
We can use openCV’s implementation of optical flow to incorporate motion information. Furthermore, after determining the knee-point, Netflix researchers described sequential models to infer the remainder of the bitrate ladder.
If all this seems like overkill, you might prefer an AWS ABR service.
Stay tuned for more updates as we apply content-aware encoding techniques to improve visual quality subject to efficient streaming!