ML on GPUs
Generally speaking, machine learning model training & inference is computationally expensive, so most practitioners know to try using GPU acceleration, if available.
Historically, these optimizations required expertise in GPU programming, especially using NVIDIA’s CUDA framework for parallel programming.
Recently, emergent best practices in model selection and transfer learning are abstracted into high-level apis, shifting the practitioner’s productivity bottlenecks from training models to getting data.
Assuming the upfront cost of developing a model to be amortized over the lifetime of it’s deployment, it becomes especially important to optimize runtime performance for your target hardware.
With NVIDIA’s latest TensorRT SDK release, one-line changes help you compile TorchScript or SavedModel artifacts optimized for fast inference using CUDA capable GPUs.
import torch
import torch_tensorrt as torchtrt
# SET trained model to evaluation mode
model = model.eval()
# COMPILE TRT module using Torch-TensorRT
trt_module = torchtrt.compile(model, inputs=[example_input]
enabled_precisions={torch.half})
# RUN optimized inference with Torch-TensorRT
trt_module(x)
Likewise, building complex video analytics pipelines can be reduced to changing configurations, or even manipulating the Graph Composer GUI in the newest release of NVIDIA’s Deepstream SDK.
While it’s easier than ever to simply put our GPUs to work and enjoy increased productivity, we are even more bullish about learning the underlying technologies enabling these gains.
Recently, we’ve been studying the exciting work in video synthesis/animation using customized CUDA kernels to warp images.
GPU Hardware
Though these MIT lecture slides compiled by Nicolas Pinto are 10 years old, they still offer an excellent motivation for GPU programming.
A key question is “How much will your workload benefit from GPU acceleration?” relating to considerations like “How parallelizable is your workload?”.
For many machine learning algorithms, training and inference entails repeated application of matrix multiplications, which can be parallelized through block multiplication. Appealing to Amdahl’s law we can estimate the theoretical gains expected through parallelized implementations.
The inherent data parallelism of certain ML workloads motivates a desire to apply more threads since CPUs are reaching physical limitations to achieving higher frequency.
Consider this excerpt from the slides referenced above:
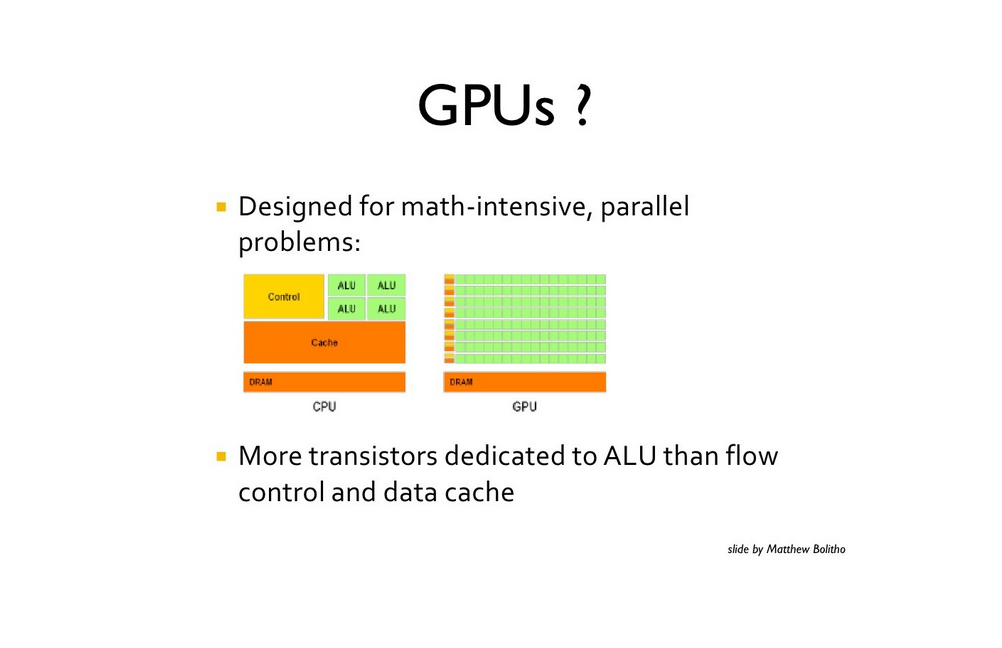
ALUs are efficient at performing low-precision arithmetic operations, though less proficient in task parallelism and context switching. Thus compared to more general processing units, they use smaller cache and amoritize the cost of managing instructions streams through single instruction multiple data (SIMD) parallelism.
GPU Software
GPUs were originally intended to support computer graphics and image processing and traditional GPU programming required casting the work in terms of rendering passes over data represented as texture maps. Over time, support for more versatile programming models was introduced.
The CUDA API enables the practitioner to hide the latency of computations with GPU coprocessors by interleaving work asyncronously over CUDA streams.
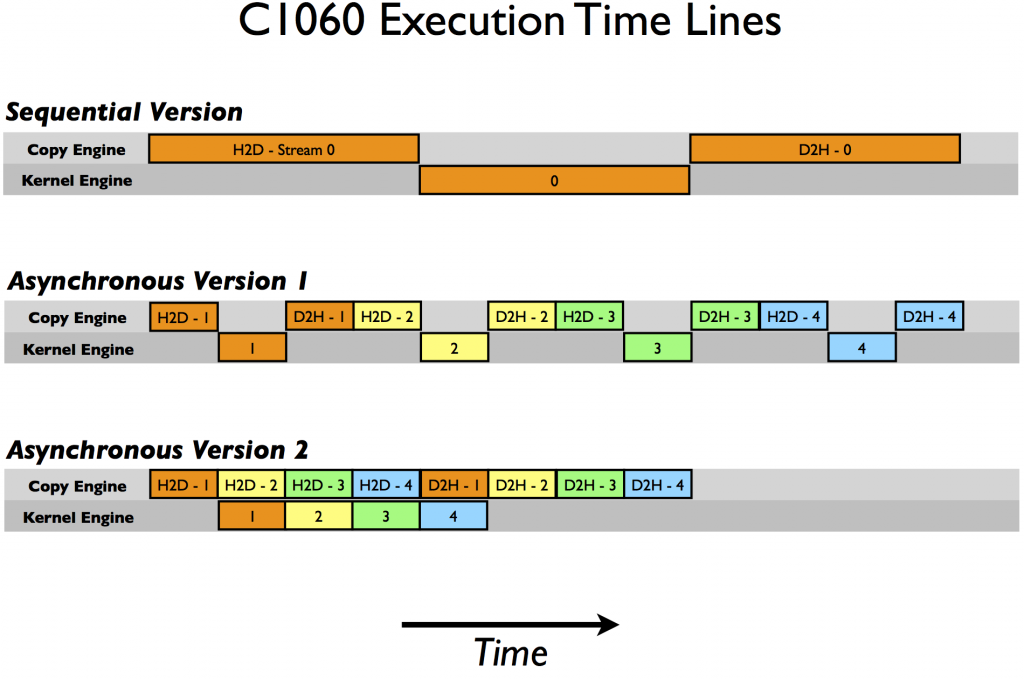
Using the NVCC compiler and declaring suitable kernel functions, C programs can achieve dramatic performance improvements. These optimizations also depend on hardware specific attributes so autotuning the kernel to the device is an important part of efficient device utilization.
With all the compute capability of this hardware, memory bandwidth typically becomes the performance bottleneck. CUDA APIs support a rich memory hierarchy for caching and exploiting data locality. The CUDA library itself is also becoming optimized to reduce memory use, allowing for more/bigger models and training batches.
Learning More
Many of the library improvements are based on continued optimizations around the contraints of heterogeneous computing. And so even a rudimentary understanding of GPU programming & design can help the practitioner realize better hardware utilization and faster iteration. However, a deeper understanding frees the practitioner to advance the frontiers of GPU programming.
We are excited about developments in libraries like CUDA and hopefully this has primed you to learn more!
Consider these resources available by library or web:
- Hands-On GPU-Accelerated Computer Vision with OpenCV and CUDA
- Hands-On GPU Programming with Python and CUDA
- CUDA by Example
- CUDA C Programming Guide
- CS 264 Massively Parallel Computing
- CS179 Notes
- PyCUDA
- Scikit-CUDA
Smell Ya Later!