Advances in methods to generate photorealistic but synthetic images have prompted concerns about abusing the technology to spread misinformation.
In response, major tech companies like Facebook, Amazon, and Microsoft partnered to sponsor a contest hosted by Kaggle to mobilize machine learning talent to tackle the challenge.
With $1 million in prizes and nearly half a terabyte of samples to train on, this contest requires the development of models that can be deployed to combat deepfakes.
Although these deepfakes can involve faked audio, most deepfake samples involve a face swap. And so many contestants concentrate their efforts on developing face detection pipelines and applying deep learning to the classification task.
Having some recent experience working with motion transfer, we were eager to consider the complementary problem of detecting deepfakes.
After reviewing some of the data samples, our intuition was guided by the observation that temporal inconsistencies make deepfakes discernable during our review.
We want to exploit a weakness in the making of deepfakes. Specifically, these methods often don’t explicitly enforce a temporal smoothness constraint.
That is why we were especially interested in a video analytics pipeline which detects and tracks faces to construct feature descriptors over time for a sequential model.
The volume of the data requires some tricks to effectively process the data. In fact, the contest submission must finish analyzing 4000 videos in under 9 hours.
We released a kernel that shows how we can skip frames and apply object tracking to quickly preprocess the data.
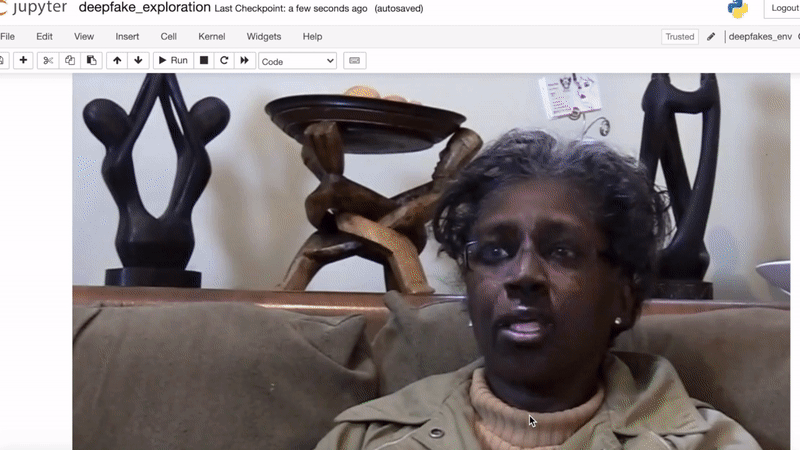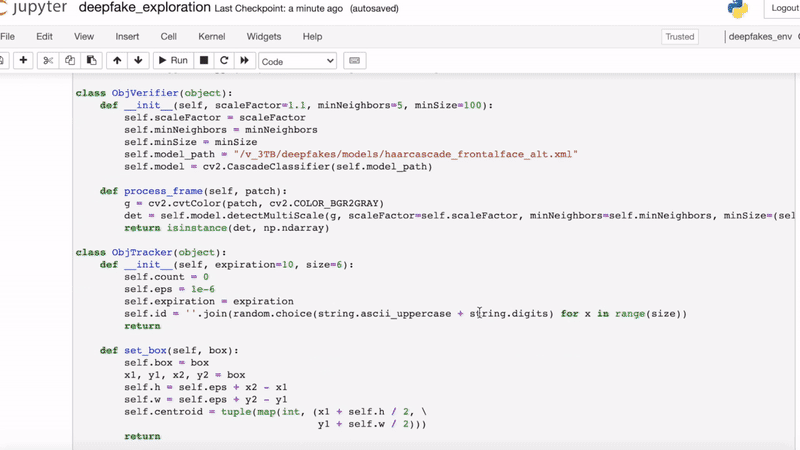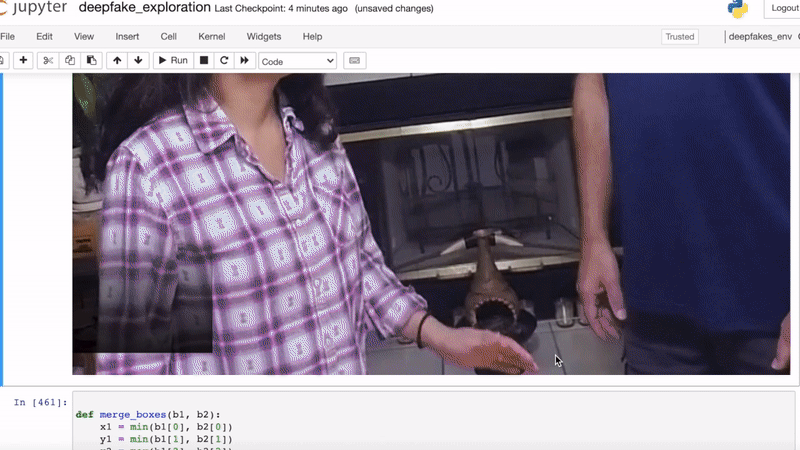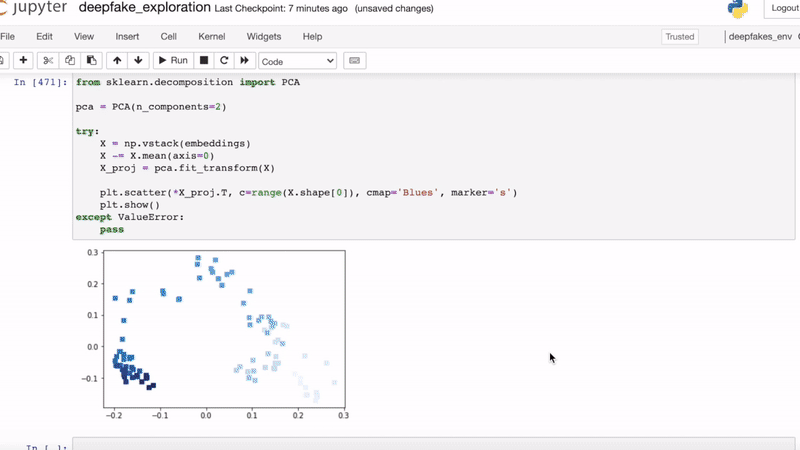
By incorporating a face embedding feature extractor, we can construct a sequential feature to feed into an LSTM. This model is basically a Long-Term Recurrent Convolutional Network with a face embedding as a fixed feature extractor.
The model is small and fast so it could be deployed as a browser plugin to validate video on the fly. We found this method to be a simple approach to detecting the discrepancies in deepfake video. The model could be improved if it were trained on more varied videos.