
Last year, over 2 thousand teams participated in Kaggle’s Deepfake detection video classification challenge. For this task, contestants were provided 470 GB of high resolution video and required to submit a notebook which predicts whether each sample video file has been deepfaked with a 9 hour run-time limit.
Since most deepfake technology performs a faceswap, contestants concentrated around face detection and analysis. Beginning with face detection, contestants could develop an image classifier using the provided labels.
Many open-source face detection libraries were considered over the contest. Aside from differences in deep learning framework, some implementations featured multi-task learning to offer facial keypoints or face embeddings in addition to bounding boxes. And because of the time-constraint, implementations supporting batch inference mode were important for faster performance.
Nonetheless, the volume of test data is too great for a frame-by-frame analysis so most contestants sampled the video a la bag-of-frames, aggregating inference results to the video level and disregarding time-space info.
Some participants used object tracking to associate bounding boxes over time for sequential models. However, fast and robust multi-object tracking is challenging enough to limit exploration during the contest.
NVIDIA’s DeepStream SDK shines in processing video with cascades of detectors and classifiers and integrates nicely with the new TLT 3.0 to train custom models.
In the remainder of this post, we highlight a simplified workflow in developing custom video classifiers using NVIDIA’s ecosystem.
For starters, this repo features reference deepstream sdk apps that you can deploy on a Jetson Nano or other compatible hardware.
We are interested in the detect-track-classify pattern using pre-trained face detection models. A similar demo performs face detection and tracking to redact personally identifiable info in video.
Bag-of-Frames Classifier Approach
Feature Engineering
After pulling and launching this docker container, we update the deepstream config file to reference a face detector. Then we can extract bounding boxes of tracked faces from our directory of videos before writing results in KITTI format.
Note: The deepstream sdk 5.x has a memory leak with long video processing jobs due to a gstreamer issue. For now, we recommend using versions 4.x or patching versions 5.x for more stability.
Here, we note that some sample videos were filmed in portrait mode. To maintain an appropriate aspect ratio for the model, it is easiest to pad the video with ffmpeg after renaming files with a bash command.
After indexing the locations of faces in time-space for our video corpus, we can extract images into a directory structure suitable for fine-tuning a ResNet base CNN for image classification with the new NVIDIA Transfer Learning Toolkit (TLT) 3.0.

Training a Deepfake Classifier with TLT 3.0
Using the TLT 3.0 requires minimal setup to fine-tune an optimized classification model on your dataset. After pip installing the launcher in your environment, you can download the Jupyter notebooks and training configs from the NGC Catalog. For this example, we use the notebook resources under the classification/ directory.
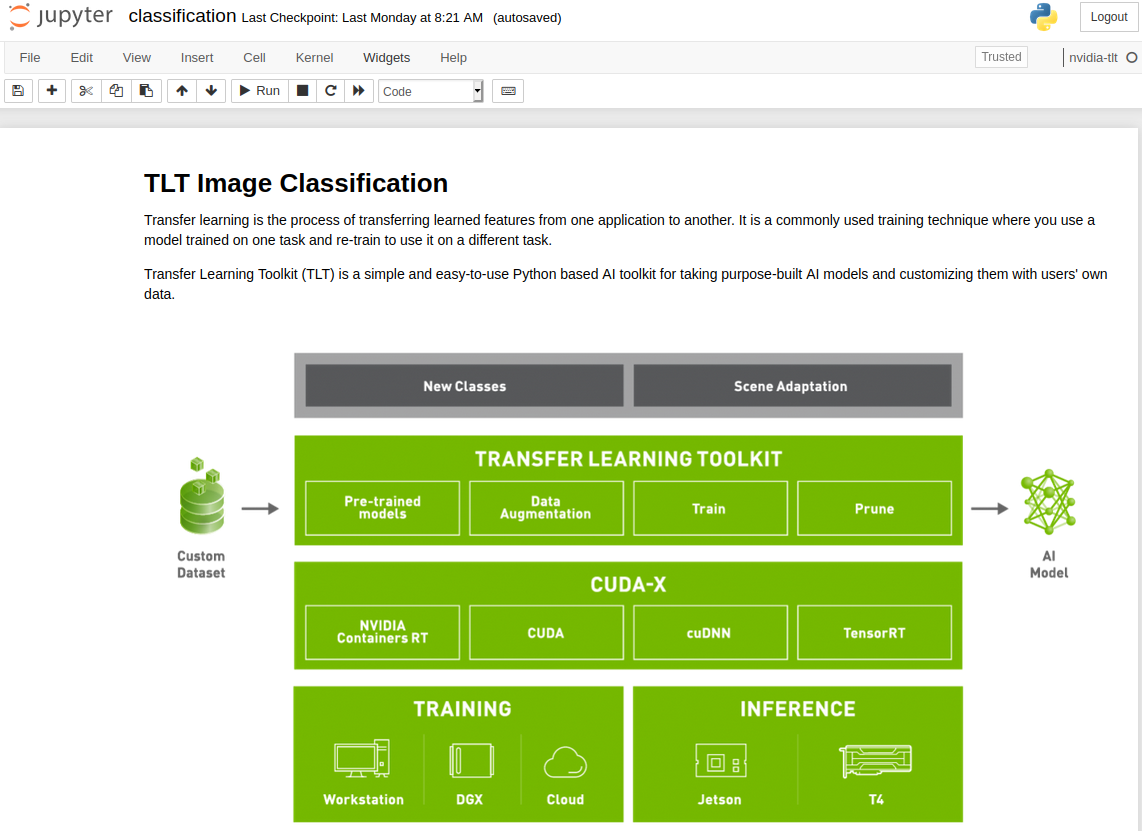
This notebook will:
- Take a pretrained resnet18 model and finetune on our dataset generated earlier
- Prune the finetuned model
- Retrain the pruned model to recover lost accuracy
- Export the pruned model
- Run Inference on the trained model
- Export the pruned and retrained model to a .etlt file for deployment to DeepStream
You can modify the default training parameters to your liking by editing the classification_spec.cfg file located in the specs/ directory. In under an hour, we had a model ready to deploy with the DeepStream SDK.
Model Deployment
After fine-tuning our model, we add it as a secondary classifier in the face detection pipeline as described here to infer whether a face crop is likely a deepfaked.

So far, the DeepStream SDK has helped to quickly and robustly index face locations in our video corpus. Within the NVIDIA ecosystem, using TLT helped to quickly establish powerful baseline image classifiers via transfer learning.
Video Classifier Approach
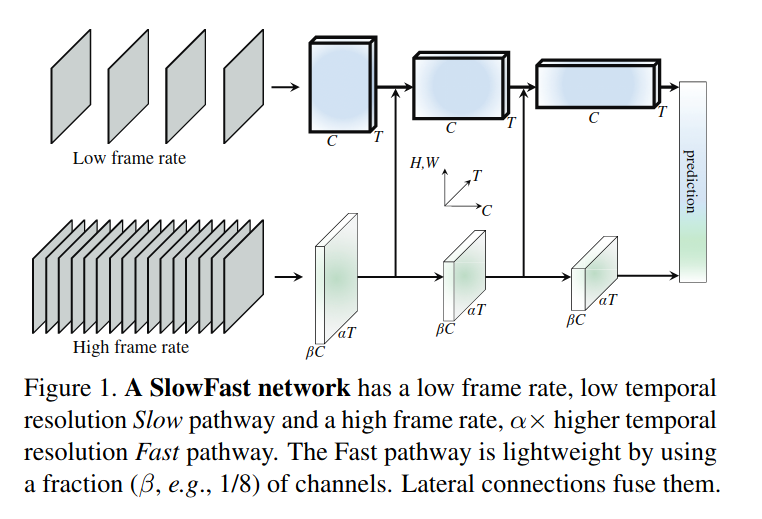
Next, we consider a video classifier used to achieve state-of-the-art results in human activity recognition, SlowFast.
The SlowFast researchers describe the biological inspiration behind the work, mimicking the function of P and M type retinal ganglion cells.
Stucturally, SlowFast uses two pathways sampling video at different rates. The slow pathway samples video frames at a lower frequency and is designed to capture high-level image features like color/texture. Conversely, the fast pathway samples video frames at higher time resolution but lower spatial resolution.
Feature Engineering
Since we have extracted thousands of videos cropped to the faces using the DeepStream SDK, we can assemble the face crops back into videos.

Then we label each clip to train our video classifier using the SlowFast model. We used a sample config that assumes a Kinetics Dataset formatted dataset.
We found the default learning rate too large for the model to effectively train on our dataset. Shrinking the learning rate by a factor of 10 resolved this for our dataset.
We also used transfer learning with a pretrained model for this new task.
The SlowFast model generates statistics like the top-k accuracy for an evaluation dataset and since we used a balanced training dataset with two classes, it was exciting to find 83% top-1 accuracy with minimal parameter tuning! We also believe additional accuracy gains can be made by refining our face detection pipeline to gather more training samples.
Summary
Winning contest entries reduced the video classification task to image classification through the bag-of-frames approach but there is plenty of additional information to use when we treat video sequentially.
Further work around the idiosyncrasies of the deepfake detection dataset, as well as hyperparameter tuning make video classifiers purposed to human activity recognition, attractive choices for this task.
We believe the SlowFast model is well-suited to the task of detecting faceswaps and in the sequel, we plan to cover some of these optimizations and compare to our LSTM model over sequences of face embeddings.