In our latest experiment with Depthai’s cameras, we consider visual localization.
This relates to the simultaneous localization and mapping (SLAM) problem that robots use to consistently localize in a known environment. However, instead of feature matching with algorithms like ORB, we can try to directly regress the pose of a known object.
This approach uses object detection, which is more robust to changes in illumination and perspective than classical techniques. And without the need to generate a textured map of a new environment, this technique can be quickly adapted to new scenes.
Localization from the Edge
The researchers note that we can choose an object detector specialized for our scene. Since they demo the Chess scene from the 7-scenes dataset, our POC will use a detector which can identify objects like a television using depthai’s mobilenet-ssd.

The next stage of the pipeline includes models specialized to fit an ellipsoid to the object’s 3D bounding box for cheap & robust pose estimation. The authors regress parameters for approximating ellipsoids as the following example shows:
By converting these models into .blob, we can set up a NeuralNetwork node to run all the heavy inference at the edge.
Here is a minimal example running the pipeline in an out-of-domain scene:
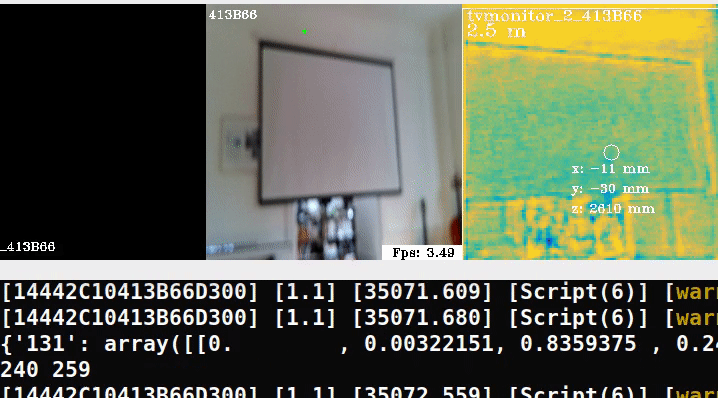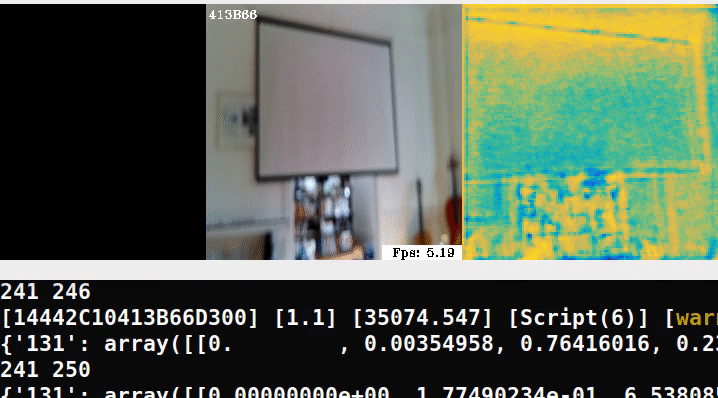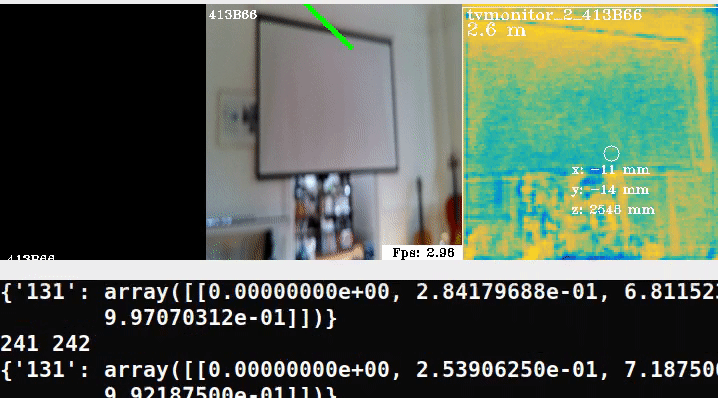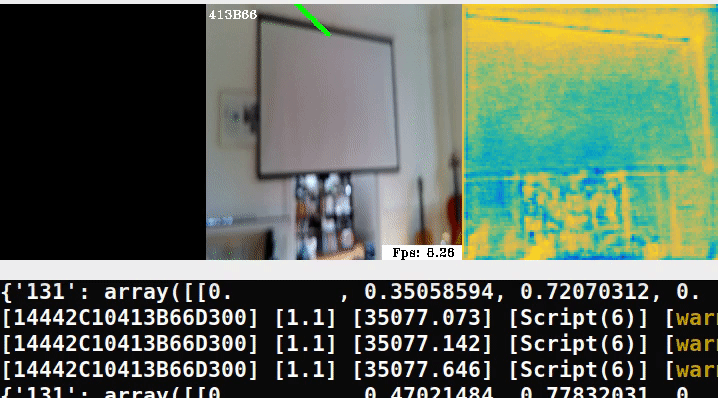
In the middle frame, we try overlaying ellipses, similar to the demo but clearly we need to retrain on our own data.
We could convert the remaining ellipsoid models from the research work into .blob format and use a script node to route messages to the appropriate NeuralNetwork node.
Such a pipeline with depthai’s SDK could look as follows:
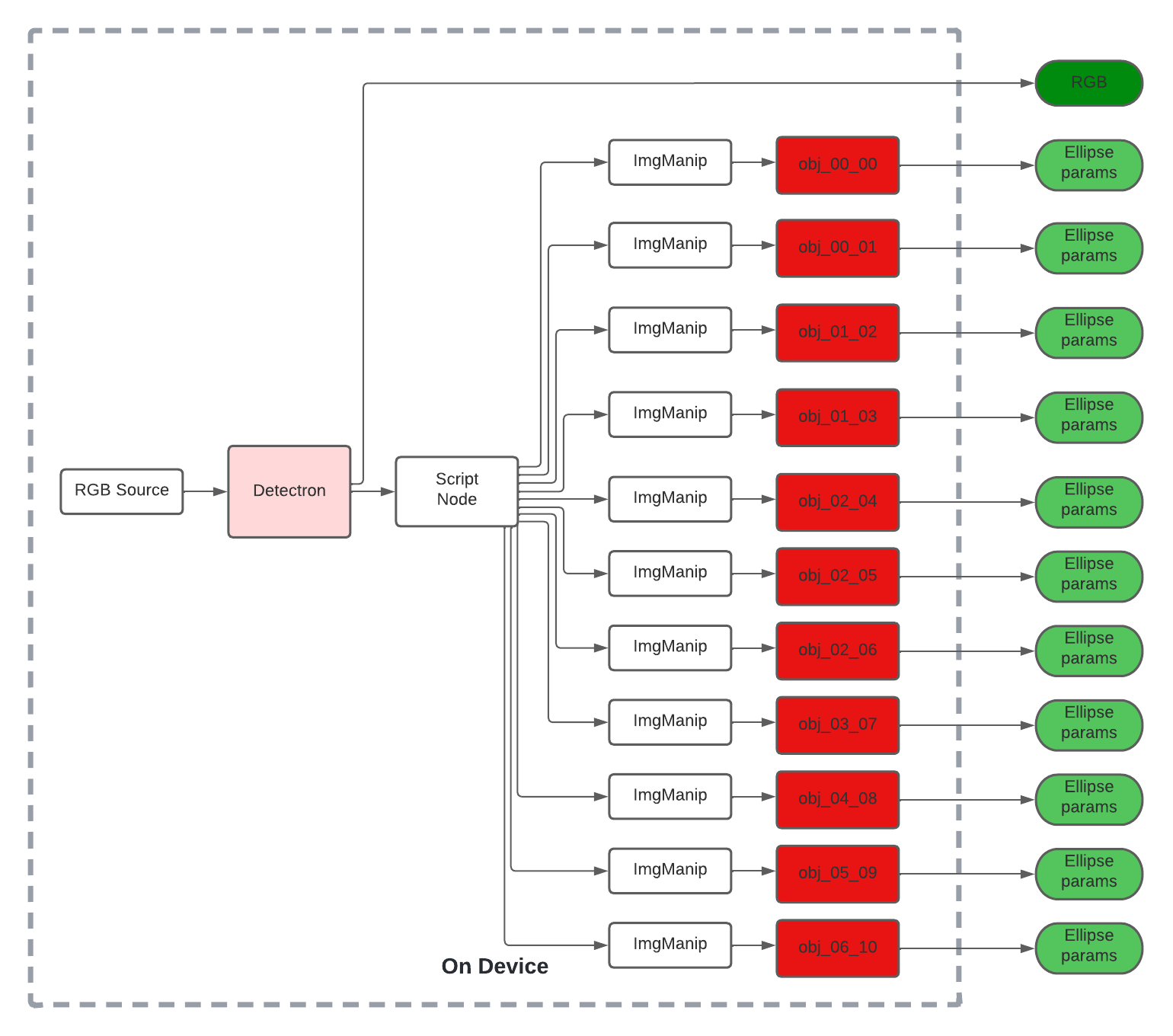
The source can be a camera or even use the XLinkIn node to stream test samples to device.
We stream RGB frames from the camera to our object detection model, the authors used Detectron while our experiment uses mobilenet-SSD.
The inference results can be parsed with a script node to route each ImgFrame to the appropriate second-stage node for ellipsoid regression.
Finally, on the host device, we can incorporate this information into a RANSAC loop to produce the final camera pose estimate.
What’s Next?
We tried running a SOTA visual localization pipeline on device using depthai’s SDK after converting models to blob.
We can try training ellipsoid models at lower input resolution or using a lighter backbone than VGG-19 to speed things up.
We can even try integrating IMUData with the 9-axis sensor on camera.
Ultimately, we can annotate a new scene file for our setting and enjoy a robust localization method with much of the heavy lifting shifted to the edge.
And soon enough, we’ll run fast INT8 models on depthai’s new cameras which upgrade to Intel’s Gen 3 Movidius: Keem Bay, stay tuned!