Check out the repo and the video!
“Everybody Dance Now” offers a sensational demonstration in combining image-to-image translation with pose estimation to produce photo-realistic ‘do-as-i-do’ motion transfer.
Researchers used roughly 20 mins of video shot at 120 fps of a subject moving through a normal range of body motion.
It is also important for source and target videos to be taken from similar perspectives. Generally, this is a fixed camera angle at a third person perspective with the subject’s body occupying most of the image.
Producing this content is challenging because it:
- Requires the user to move around in front of a camera for 20 mins
- Involves training custom GAN from scratch
We want to explore model and implementation reductions with the goal of quickly producing ‘reasonable quality’ motion transfer examples in a live demo.
Before framing this further, let’s pause to consider specific challenges to producing qualitatively satisfactory examples.
Gallery of GANs Gone Wrong
In each of the following experiments, we use no more than 3 minutes of sample target video shot at 30 fps.
The first example shows how errors in pose estimation, particularly false positives on shadows, can be rendered as an unrealistic backup dancer.

Next, GANs are difficult to train, this example appears to suffer from mode collapse as well as challenges related to perspective from a tight framing.

Pose estimation models simply don’t perform well in some body positions. Specifically, occlusion of the head or a relatively low framing of the upper body can impact pose estimate quality. The next example demonstrates an attempt at motion transfer of a yoga flow.

The next two are more convincing but each highlights the challenges in reproducing complex scenes.

Finally, we reach something closer to an entertaining example of motion transfer content.

Motivated by a sense of how our our experimental designs have impacted the quality of the renditions, we can constrain our demo to more consistently produce high quality examples.
Setting the Scene
Simple scenes are easiest to generate. This reduction will help us spend our practical compute budget refining models to produce hi fidelity renditions of the subject dancer.
Also, researchers emphasized slim fit clothing to limit the challenges of producing complex textures. For our purposes, we assume participants will wear attire typical to a tech or business conference.
Additionally, we want to assume the scene is an adequately lit booth with the space to frame a shot from a similar perspective to that of the source reference video.

The example above shows an idealized setting for our booth after training an image-to-image translation model on roughly 5 thousand 640x480 images.
Note the glitchy frames due to poor pose estimation at the feature extraction step on the source dance video.
Estimating Pose at the Edge
Motion transfer involves a costly feature extraction step of running pose estimates over source and target videos.
However, reference source videos should be assumed to be available and processed ahead of performing the transfer.
The new Coral Dev board (EdgeTPU) can run pose estimation at roughly 35 fps for 481x353 images using TFLite. For 640x480 images, we can run inference inline with frame acquisition at roughly 25 fps.
To achieve the greatest time resolution using hi-speed cameras, we would not block frame acquisition with inference and streaming, but could instead write images to an mp4. Then the video file can be queued for asynchronous processing and streaming.
Assuming a realistic time budget from a user in our booth, say 15 seconds, we can increase the number of edgeTPUs & hi-speed USB cameras until we can ensure acquiring sufficiently many training samples for the GANs.
We’ve also seen how pose estimate quality impacts the final result. We choose larger, more accurate models and apply simple heuristics to exploit continuity of motion.
More concretely, we impute missing keypoints and apply time smoothing to pose estimates en-queued into a circular buffer. This is especially sensible when performing hi-speed frame acquisition.
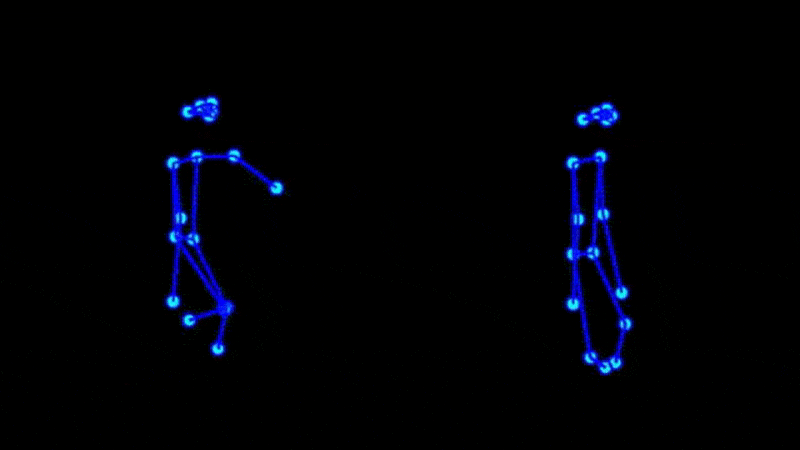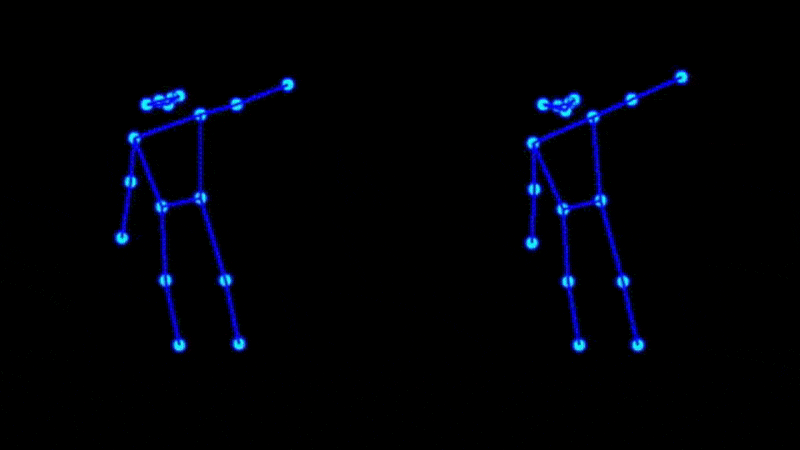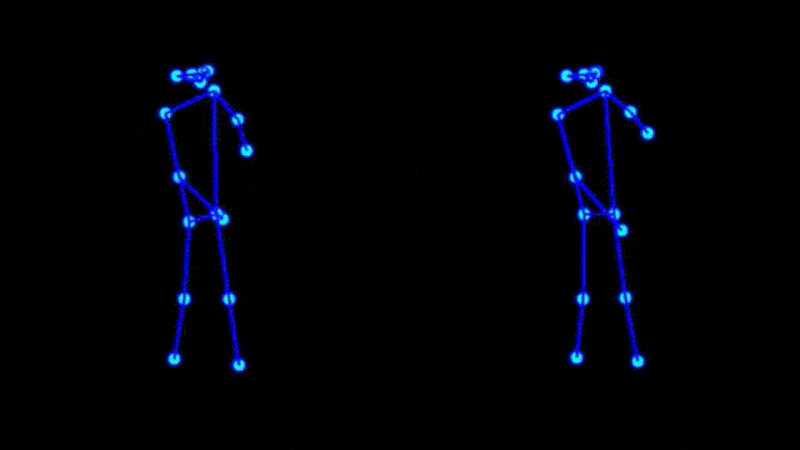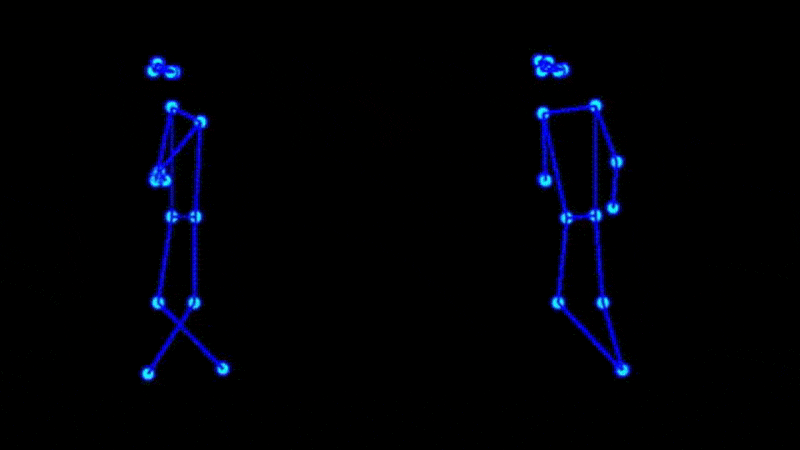
The main impact to final quality comes from poor pose estimates generated from the source video. As valuable reference videos processed ahead of time, these should be corrected manually if necessary.
Streaming the inference results to the cloud, we generate a training corpus for our image-to-image translation models.
Then the main bottleneck to quickly producing one of these examples in in training the GANs.
This reference implementation was run for roughly 8 hours on a GTX 1080 GPU. We want to get training times down to 1-hour so we will need something quite different.
Next, we discuss some implementation choices to expedite the production of motion transfer examples in a live demo setting.
Yo Dawg, I heard you like to Transfer…
…So we’re gonna apply transfer learning to this motion transfer task.
In other words, having trained a motion transfer model for one target dancer, we can use this model as a warm starting point to fine tune models for other dancers in the same scene.
Our setup thus far takes a few seconds to acquire images before running inference at the edge and pushing the results to the cloud. This means we have one hour to fine tune a model restored from a checkpointed one trained over hours ahead of time on our demo setting from above.
Since we use identical but flawed pose estimates from before, the following examples shows the same ‘glitch’ behavior. This is easily corrected in source video ahead of the demo day.
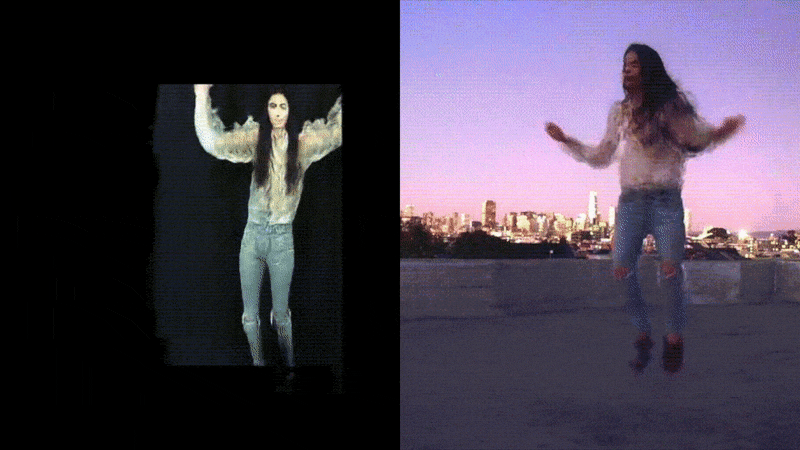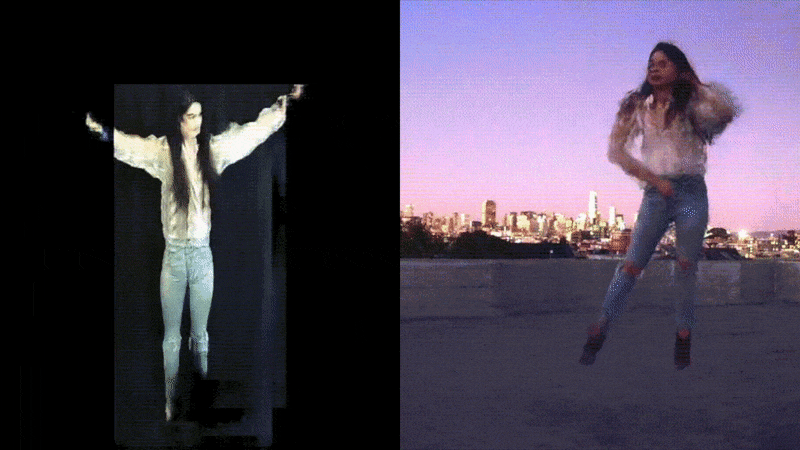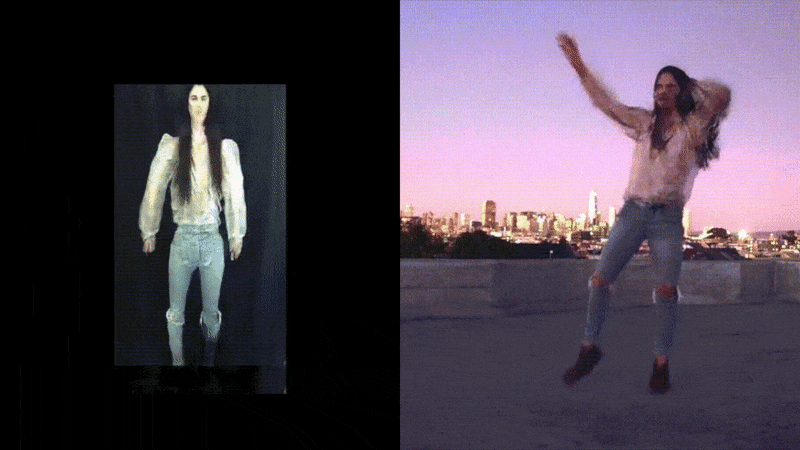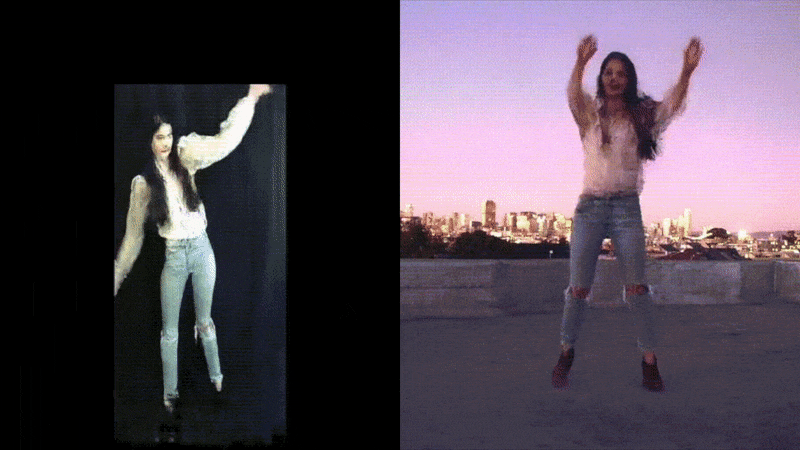
The above examples used transfer learning from checkpoints already trained to produce reasonable motion transfer renditions in our demo and rooftop environments, respectively. The booth setting on the left trained in only one hour, however, the complex rendition on the right took considerably longer.
This means we can invite users into our booth and let them move through a full range of motion in front of our array of cameras and edgeTPUs for a few seconds.
This setup will be acquiring thousands of photos and running inference in real-time before streaming results to the cloud.
In the cloud, we run a server to train the GAN for our one hour time budget before sending a user video links to hosted renditions.
By implementing pix2pix for cloud TPUs, we might expect similar results to be attainable in minutes!
Twisting the Task
The person segmentation result, BodyPix, was published after “Everybody Dance Now” but offers an alternative to pose estimation for the intermediary representation used in motion transfer.
We might expect the BodyPix alternative to provide:
- a smoother representation of body part location by virtue of representation as a region rather than a point
- 2D regions offer more implicit information on orientation than can be encoded with a line segment
- greater pose resolution with 24 regions compared to 19 keypoints w/ pose estimation
The model is only available as a demo to use with tensorflow.js in the browser. For our proof-of-concept, we modify the demo so we can build the dataset to leverage person segmentation for motion transfer.
The newest version of BodyPix also features multi-person inference so we tried to recreate a Kali fight scene featuring two people. We took a video of ourselves trying to move like fighters with sticks. From this video, we extracted pose estimates, color coded for each individual, and used BodyPix for body part segmentation.
We found that using BodyPix in addition to pose estimation lets us transfer body shape as well as motion!

First-Order Motion Model
Finally, we explore applying the techniques of “First-Order Motion Models for Image Animation”.
In this work, researchers introduce a semi-supervised learning formulation to disentangle the tasks of modeling motion and appearance for a target object class.
Then we can extract the keypoints from a driver video and use the appearance of a target image to produce motion transfer in one shot.
This means we don’t need to fine-tune a GAN for each individual! Instead, we can learn a motion model from a corpus of dancers and generate our motion transfer from a single image.

You can see the model lacks the same capacity to generate realistic images as StyleGAN variants, however, this technique applies to object classes which have no existing pose estimation model.