Check out the repo and enjoy the video on YogAI and ActionAI
Wanting a personal trainer to help track our fitness goals, we figured we could build our own. The goal was to build an application that could track how we were exercising and began with Yoga as a simple context. We dubbed our first iteration of this application as YogAI.
We thought about the YogAI concept for some time. Initially, we envisioned a smart yoga mat based on computer vision for corrective posture advice. We found out that others have taken the approach of embedding sensors within the yoga mat, although it appears they too are interested in vision.
We returned to the idea after seeing interesting work using pose estimation that we wanted to reproduce. However, we decided to put YogAI on a smart mirror platform.
By framing photos from the perspective of a large mirror on the wall rather than on the ground from a yoga mat upward, we could train models using yoga photos from the wild. These typically feature full body perspective from a distance at a height typical of a photographer.
Making a smart mirror is simple enough: just need an old monitor, a raspberry pi, and a one-way mirror, see how we built it here. We add a camera and microphone to support VUI and a visual analysis of the user, all taking place on-device.
To evaluate our concept, we begin by gathering images of Yoga poses with an image search for terms like: ‘yoga tree pose’, ‘yoga triangle pose’, etc. We chose yoga because the movements are relatively static compared to other athletic maneuvers, this makes the constraints on frame rate of inference less demanding. We can quickly filter out irrelevant photos and perhaps refine our queries to build a corpus of a couple thousand yoga pose images.
We’d love to achieve the speed of a CNN classifier, however, with only a few thousand images of people in different settings, clothing, positions, etc. we are unlikely to find that path fruitful. Instead, we turn to pose estimation models. These are especially well-suited to our task of reducing all the scene complexity down to the pose information we want to evaluate. These models are not quite as fast as classifiers, but with tf-lite we manage roughly 2.5 FPS on a raspberry pi 3.
Pose estimation gets us part way. To realize YogAI, we need to add something new. We need a function that takes us from pose estimates to yoga position classes. With up to 14 body keypoints, each of our couple thousand images can be represented as a vector in a 28-dimensional real linear space. By convention, we will take the x and y indices of the mode for each key point slice of our pose estimation model belief map. In other words, the pose estimation model will output a tensor shaped like (1, 96, 96, 14) where each slice along the final axis corresponds to a 96x96 belief map for the location of a particular body key point. Taking the max of each slice, we find the most likely index where that slice’s keypoint is positioned relative to the framing of the input image.
This representation of the input image offers the additional advantage of reducing the dimensionality of our problem for greater statistical efficiency in building a classifier. We regard the pose estimation process as an image feature extractor for a pose classifier based on gradient boosting machines, implemented with XGBoost.
Then we were able to quickly demonstrate our approach by training a gradient boosting machine. It didn’t take much parameter tweaking before we were able to evaluate our pose estimation model.
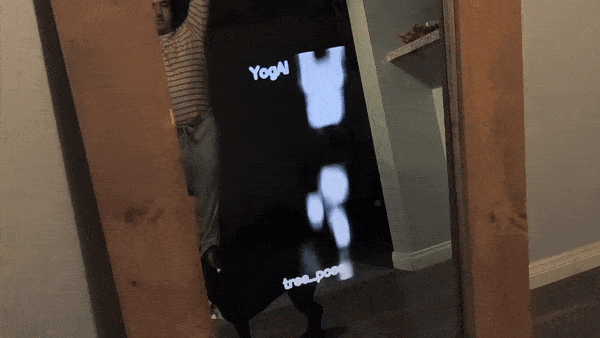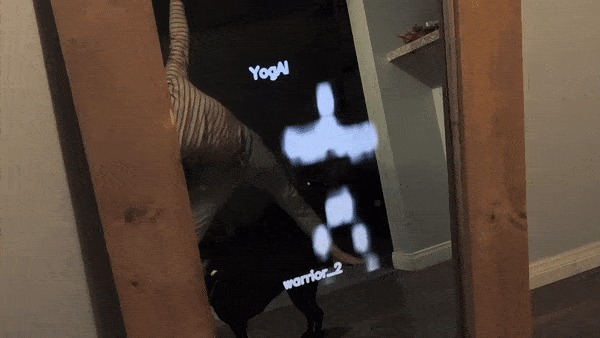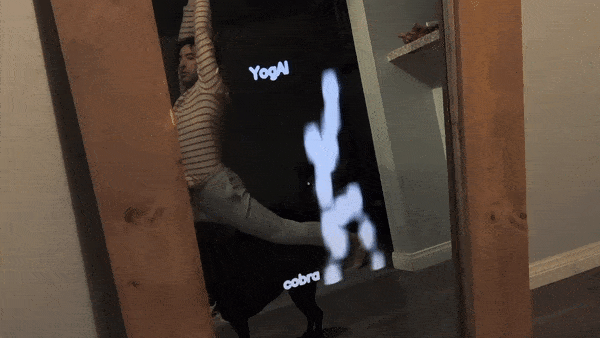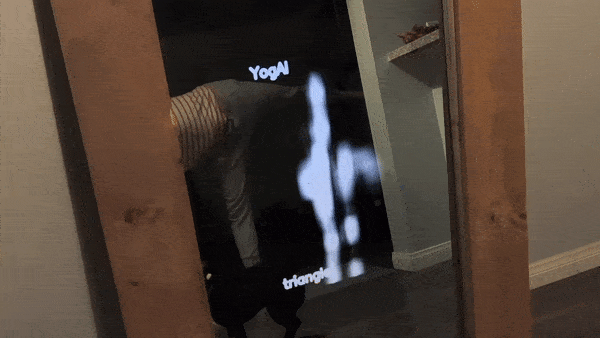
Shortly after, the proof of concept got covered in MagPi Magazine!

It was natural to consider how we might use pose estimates over time to get a more robust view of a figures position in the photo. Having built a reasonable pose classifier, this also begs the question how we might generalize our work to classifying motion.
Our first idea here was to concatenate the pose vectors from 2 or 3 successive time steps and try to train the tree to recognize a motion. To keep things simple, we start by framing a desire to differentiate between standing, squatting, and forward bends (deadlift). These categories were chosen to test both static and dynamic maneuvers. Squats and Deadlifts live on similar planes-of-motion and are leg-dominant moves though activating opposing muscle groups.
We found a couple youtube videos of high repetition moves performed by fitness athletes filmed from a perspective similar to the design of our smart mirror. We split the videos using ffmpeg and ran pose esimtation to get our pose vector representation of each frame after some minor edits to cut out irrelevant video segments.
Our gradient boosting machine model seemed to lack the capacity to perform reasonably. We decided to apply LSTMs to our sequence of pose vectors arranged in 28xd blocks, sweeping d in {2, 3, 5}. After some experiementation, we determined that 2 LSTM blocks followed by 2 fully connected layers on a 28x5 input sequence yielded a reasonable model.
Now we have basic motion classification!

Introducing ActionAI
Advancements in edge devices specialized for machine learning training/inference on device and various machine learning libraries improving inference time on pose estimation models gave way for improvements in FPS for classifying poses and movement.
We abstracted the technique of using pose estimation inference output as input for an LSTM classifier into a toolkit called ActionAI. It’s prominently feaured in GitHub’s human action recognition topic and received a prize in NVIDIA’s AI at the Edge Challenge!
ActionAI generalizes the approach of YogAI and related projects framing an IVA pipeline by introducing trackers and multi-person pose estimation.
By baking pose estimation into the pipeline as the primary inference engine, the developer can focus on training simple image classification models based on low dimensional features or small, localized image crops.
Since popular IVA frameworks typically only support the most common computer vision tasks like object detection or image classification/segmentation, we needed to implement our own.
Many IVA frameworks use GStreamer to acquire and process video. For our video processing demo, OpenCV suffices. For pose estimation we use Openpose implemented with popular deep learning frameworks like Tensorflow and Pytorch.
Accurately recognizing some activities requires higher resolution in time with higher frame rates, so we use TensorRT converters for optimized inference on edgeAI prototyping devices like the Jetson Nano.
The main programming abstraction of ActionAI is a trackable person class, similar to this pyimagesearch trackable object. This object has a method to enqueue the configuration of N (14 or 18) new keypoints as a length 2N numpy array into a circular buffer. For computational efficiency, we prefer smaller buffers, but we balance this desire with one to provide enough information as input for secondary models. This object also encapsulates ids, bounding boxes, or the results of running additional inference.

To track person instances, we used a scikit-learn implementation the Kuhn–Munkres algorithm based on the intersection over union of bounding boxes between consecutive time steps. This blog has nice exposition on applying this algorithm to perform matching.
Like other IVA frameworks, we incorporate visual overlays to support ML observability and introspection as well as visual storytelling.
In another direction, by polling for button presses of a PS3 controller connected to the Jetson Nano by USB, we easily annotated activities for person instances at each time step interactively, like we did with the MuttMentor.
This makes an ideal prototyping and data gathering platform for Human Activity Recognition, Human Object Interaction, and Scene Understanding tasks with ActionAI, a Jetson Nano, a USB Camera and the PS3 controller’s rich input interface.

In YogAI, we found sequences of pose estimates to be powerful features in recognizing motions from relatively few samples. In ActionAI, by running model update steps inline with image acquisition and PS3 controller annotation, we can implement a demo similar to the teachable machine.
We hope by sharing this toolkit, others are more easily able to classify their own set of actions at the edge. Some have suggested using ActionAI for identifying their karate katas or dance.