
We have seen applications in industries like retail, telemedicine, and robotics enabled by video analytics with machine learning. ML practitioners often leverage transfer learning with pretrained models to expedite development. Computer vision applications can benefit from using video analytics frameworks to facilitate faster iteration and experimentation.
NVIDIA’s TLT toolkit and the Deepstream SDK 5.0 have made it easy to experiment with various network architectures and quickly deploy them on a NVIDIA powered device for optimized inference.
To experiment with these new software, we used the TLT toolkit to fine tune a detectnet_v2 model on a fashion dataset to detect dresses, jeans, and tshirts. Then we used the new Deepstream SDK 5.0 to deploy the model on a Jetson device for a smart personal wardrobe assistant we nicknamed Stilo.
Training with the TLT toolkit
We curated a small dataset from the Human Parsing dataset and transformed it into the KITTI format.
NVIDIA has released a docker container with TLT configured and includes a directory of jupyter notebooks with examples on how to fine-tune various model architectures from their model zoo.
Following the detectnet_v2 example notebook includes all the config files needed to properly train, prune, retrain, and deploy a model.
Train
To train, we used the GPU configuration:
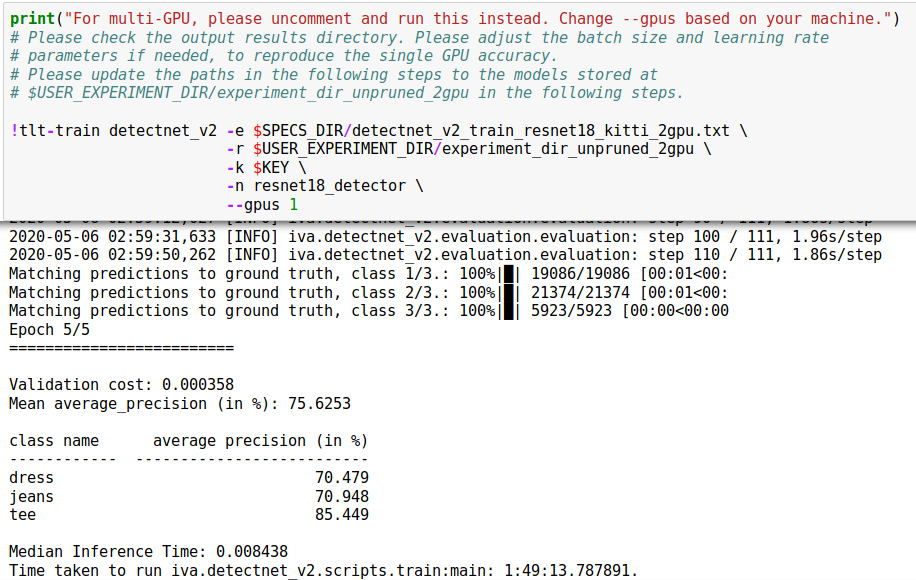
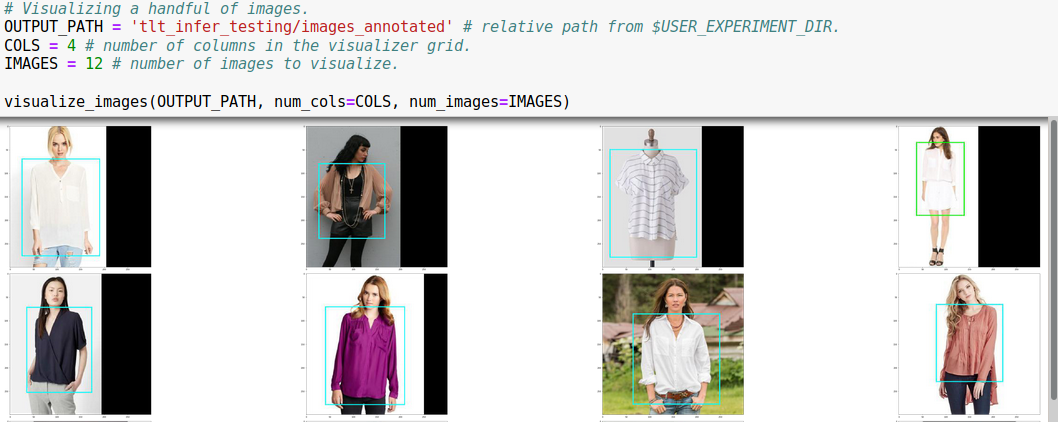
It’s also very easy to visualize the results for a quick sanity check:
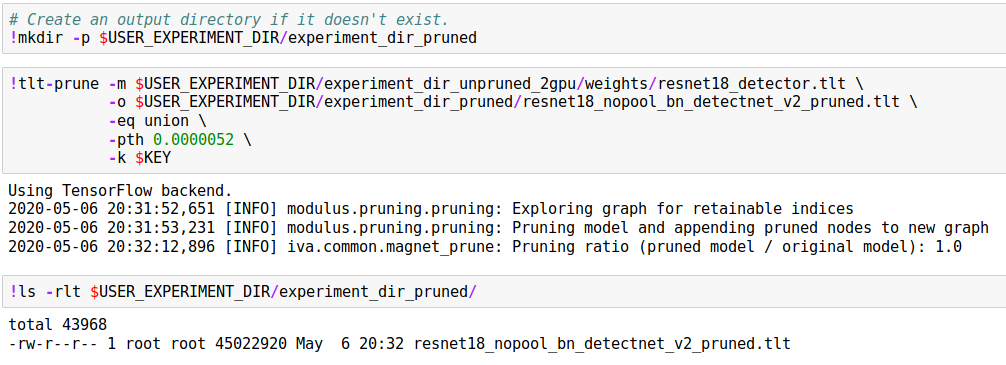
Prune
Next we prune our model. Pruning helps reduce the memory footprint of the model and increases inference speed.
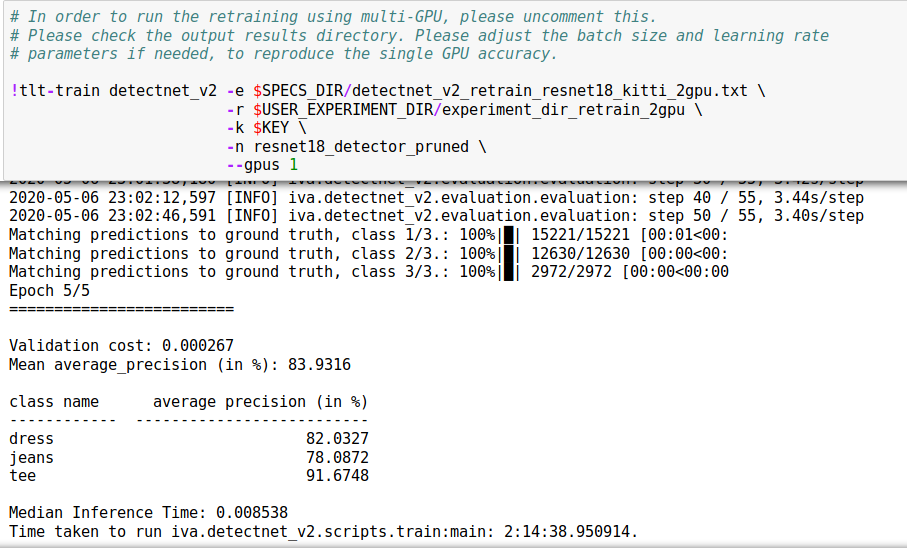
Retrain
Next, we retrain the pruned model, bumping up the performance of our model by almost 10%!
Deployment with the Deepstream SDK 5.0
The Deepstream SDK was designed to help developers build high-performance, machine learning based real-time video analytics applications. It is as simple to use as the TLT toolkit, boiling down to editing a few config files and running the command line interface.
To use the SDK, you can use a docker container configured with the Deepstream SDK or install it directly on your device.
The SDK also comes with lots of examples on how to deploy multiple models, with a variety of inputs (file, camera) and outputs (file, RTSP Stream). Since the SDK is based on GStreamer, it is flexible on input and output interfaces it can process.
Deploy
We used an example from the tlt pretrained model config examples found in /opt/nvidia/deepstream/deepstream-5.0/samples/configs/tlt_pretrained_models.
We simply added a label file with our three categories:
# in a file called labels_fashionnet.txt
dress
tee
jeans
You can take an example config_infer_primary file like config_infer_primary_peoplenet.txt and point to you model assets:
# modify the following:
[property]
tlt-encoded-model=<TLT model>
tlt-model-key=<Key>
labelfile-path=<Label file>
int8-calib-file=<INT8 Calibration cache>
input-dims=<Inference resolution>
num-detected-classes=<# of classes>
Finally, we copied an example deepstream_app_source1 file from the peoplenet example to point to our new config_infer_primary file above.
[primary-gie]
# near the bottom of the section
config-file=config_infer_primary_fashionnet.txt
Now just run deepstream-app -c deepstream_app_source1_fashionnet.txt.

The TLT toolkit and Deepstream SDK simplify training and deployment of models optimized for streaming video applications. Prototyping IVA applications can be reduced to modifying configuration files.
For our prototype, this helped us quickly evaluate a real world video stream. To improve performance, we would add more training samples that look closer to our deployment scene inside a closet.