Like others, we’ve noted a recent uptick in research implemented using Jax. You might chalk it up as yet another ML platform, but Jax is emerging as the tool of choice for faster research iteration at DeepMind.
After exploring for ourselves, we’re excited to find Jax is principally designed for fast differentiation. Excited because differentiation is foundational to gradient-based learning strategies supported in many ML algorithms. Moreover, the derivative is also ubiquitous in scientific computing, making Jax one powerful hammer!
A Whiff of AutoDiff
We found this excellent survey on automatic/algorithmic differentiation (autodiff) and differentiable programming quite illuminating.
Recall back in calculus, we conceptualized the derivative as a limit of successively better approximations to the tangent space of a function at a point. This perspective motivates numerical differentiation techniques like the finite difference method. The convergence of these methods is challenged on the one hand by sensitivity to choice of step size and the other by an accumulation of round off errors.
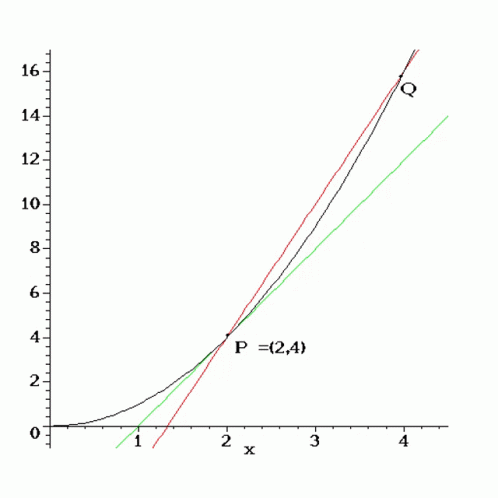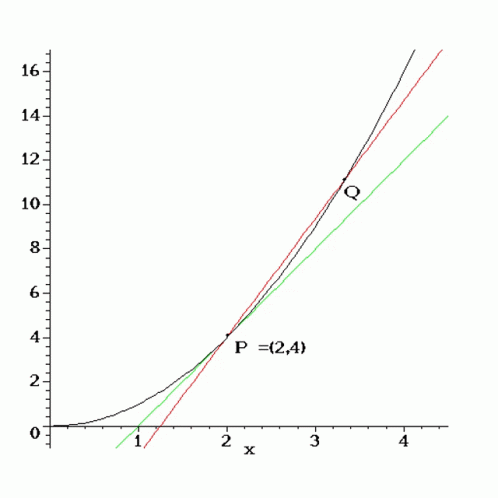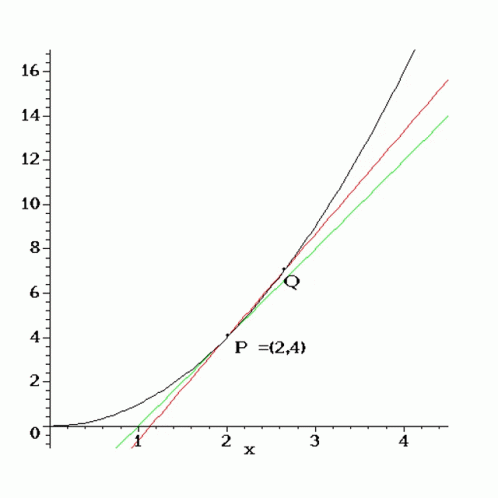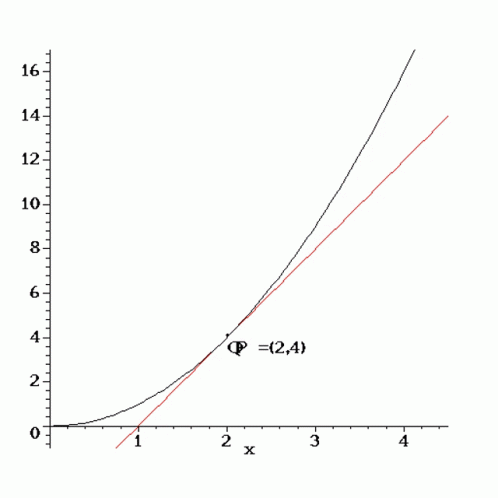
A little further into calculus, we learned simple rules for differentiating algebraic and transcendental functions. We learned how the derivative interacts with function composition as well as other operators like the sum and product. These insights shaped symbolic differentiation techniques used in tools like Mathematica. Unfortunately, this approach suffers from an explosion of terms when computing derivatives for function compositions, no good for deep learning.
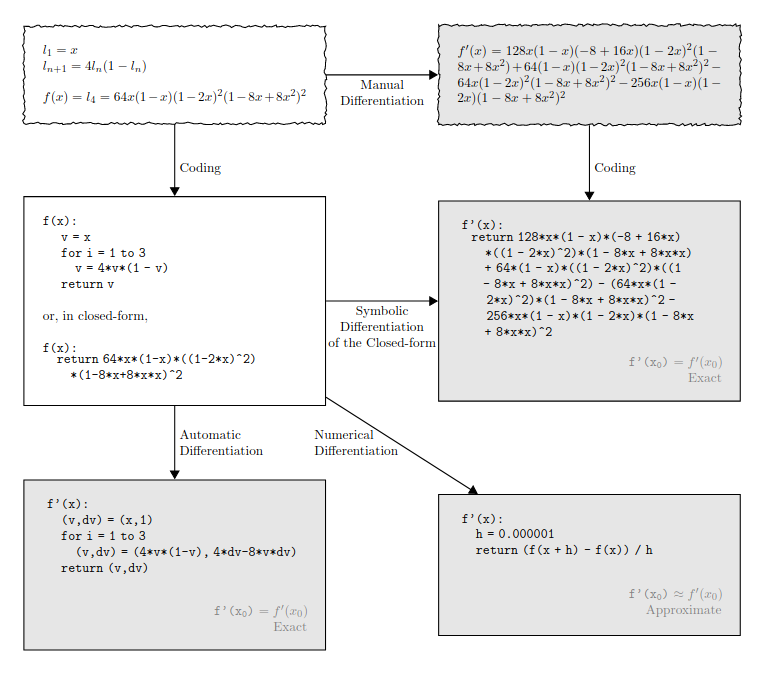
Jax takes a different tack with autodiff. This endows Jax with the ability to translate your code into certain primitives for which the derivative is known, akin to symbolic differentiation. Crucially, these primitives include control flows like branching and looping, making it simple to just apply the dang derivative.
Unlike symbolic differentiation, autodiff uses a computation graph to efficiently determine and accumulate function values and derivatives. With respect to the computation graph’s topological ordering, we consider forward and reverse mode AD. Deep learning practitioners are already familiar with backpropagation, which can be realized as reverse mode auto differentiation.
Just the gist of jit, xla, vmap
The Jax compiler optimizes high-level code for xla by way of a statically-typed expression called a jaxpr. Jax naming and typing help to manage complex, structured data through the pytrees api.
The Jax transformation model emphasizes pure functions, implying some consideration required for handling stateful computations.
Jax can trace a program with jit to generate fused operations over reduced-precision numeric representations optimized for hardware accelerators.
Jax is designed to easily support the data and model parallelism used to efficiently scale up training of ML models. Vectorizing a transformation is trivial with vmap.
Jax Docs Rock!
The official documentation is full of demos highlighting the unique capabilities of the tool!
For instance, with easy, scalable differentiation, you can wrangle nonlinearity by implementing fixed point solvers using the vector-jacobian product or even make a custom VJP for integration over a riemannian manifold.
This example shows how temporal-difference updates can be cast as derivatives of a pseudo loss function while using Jax’s fine-level control of gradient computations to tackle problems in RL.
Google researchers show Jax solving PDE like the wave equation or Navier-Stokes.

A favorite example generates images after learning the vector field arising from the gradient of log data density p(x) w.r.t x. Learning is accomplished by annealing the amount of perturbative noise applied to examples during training. In the end, randomly initialized points can seed trajectories which flow along the vector field to iteratively refine generated samples via Langevin dynamics!

Conclusion
Randomization and the derivative offer two powerful analytical tools to approach broad problem classes. Combining randomization with differentiation helps to scale learning through fast linear approximations.
Lately, I’ve been revisiting studies in scientific computing and machine learning to consider innovations at the intersection of these disciplines. Perhaps Jax will accelerate the convergence of ML & scientific computing with an abstraction that appropriately elevates the derivative.
We’re just getting started but Google makes it easy to borrow TPUs so you too can join us in a jaxtragavanza of experiments in computing this Summer!