The use of streaming services has sharply increased over this past year.
Many video streaming platforms prominently feature theatrical posters in content representation.
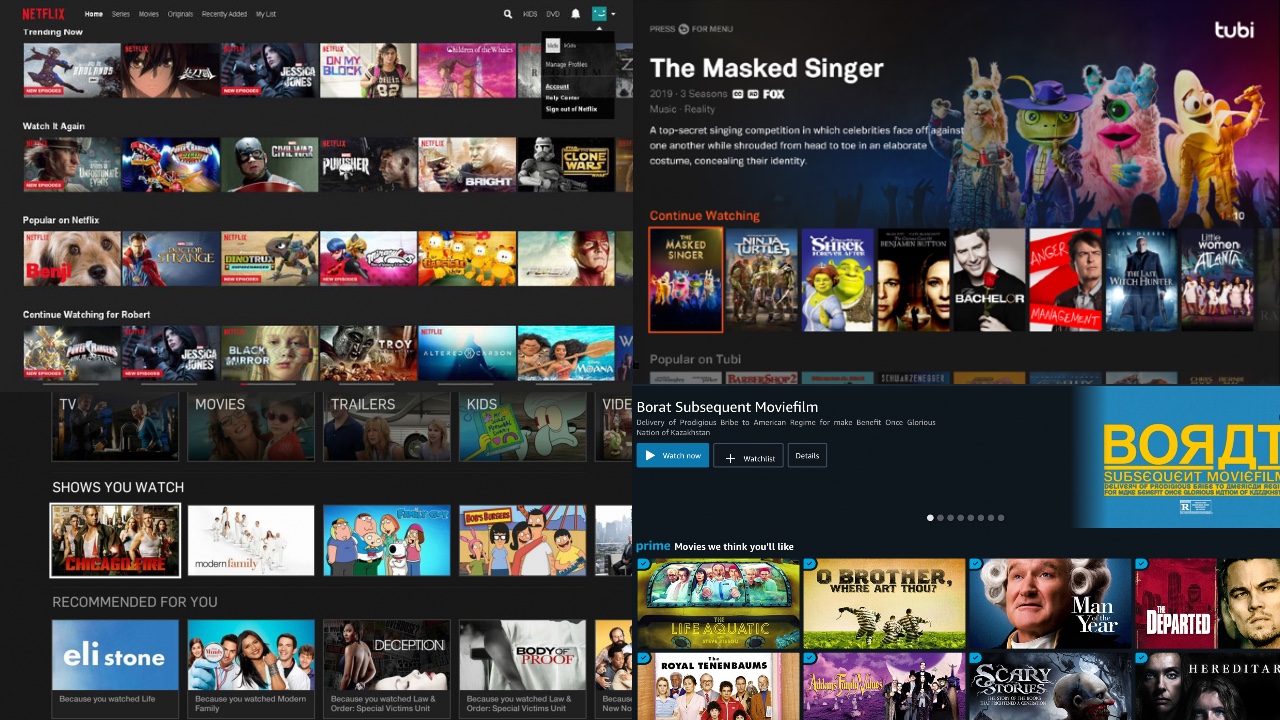
As movie posters are designed to signal theme, genre and era, this representation strongly influences a user’s propensity to watch the title.

Domain experts have remarked on how poster elements can convey an emotion or capture attention.
Exploring this thesis, Netflix conducted a UX study, using eye tracking to find that 91% of titles are rejected after roughly 1 second of view time.
In this project, we develop models to learn movie poster similarity for applications in content-based recommendations.

Genre information and Weak Labeling
In poster design, genre is often conveyed through low-level information like color palette in addition to higher-level structural and semantic indicators. For instance, an actor’s uniform may indicate the movie is about baseball.
Though easy to frame a classification task by aligning a title’s poster with genre labels, we ultimately seek embeddings transcending these labels to capture semantic similarity.
Metric Learning
Some describe using learned embeddings from the penultimate layer of a multilabel classifier as a representation for movie posters. In fact, Pinterest researchers find this approach performing on par with metric learning approaches.
However, this recently open-sourced module simplifies setting up metric learning tasks using weakly labeled images. This loss is more directly optimized for the task of measuring image similarity and it trivializes mining suitable triplets and learning with a margin-based loss.
Putting it Together
Movie posters are relatively complex compared to some image datasets like MNIST or FashionMNIST.

Qualitatively, we consider the complexity of this dataset between that of FashionMNIST and ImageNet. Therefore, we apply transfer learning from base networks pre-trained on ImageNet. Characterizing the intrinsic dimensionality of our movie poster dataset can be put on more precise quantitative footing using entropy measures like these researchers showed.
from tensorflow.keras import Sequential, layers, applications
model = Sequential([
layers.Lambda(lambda x: applications.nasnet.preprocess_input(x)),
applications.NASNetLarge(include_top=False, input_shape=(331, 331, 3),
weights="imagenet", pooling="avg"),
layers.Flatten(),
layers.Dense(128, "linear", name="embedding"),
layers.Dense(num_genres, name="logit")
]
)
We also explore a warmup phase of fine-tuning a genre classifier before changing loss for metric learning. In this way, we initially compile with the keras.losses.BinaryCrossentropy(from_logits=True) loss.
We also found it helpful to progressively unfreeze lower blocks over the course of several training epochs using a method like this:
self.blocks = ["_18"]
def freezeAllButBlocks(self):
self.model.trainable = True
for i, block in enumerate(self.model.layers):
if block.name == "NASNetLarge":
if not self.blocks:
block.trainable = False
else:
for l in block.layers:
if not l.name.startswith(tuple(self.blocks)) or \
isinstance(l, layers.BatchNormalization):
l.trainable = False
return self.model
Ultimately, we find higher capacity pretrained base network architectures like NASNet most performant. After this preliminary burn-in phase, we extract the model up to the logit layer with:
warm_model = keras.Model(
model.input, model.get_layer("embedding").output
)
Incorporating the angular loss and following the guidance of these researchers, we tune the margin parameter for the dataset. We found smaller values of angular margin helpful: tfa.losses.TripletSemiHardLoss(distance_metric="angular", margin=0.1).
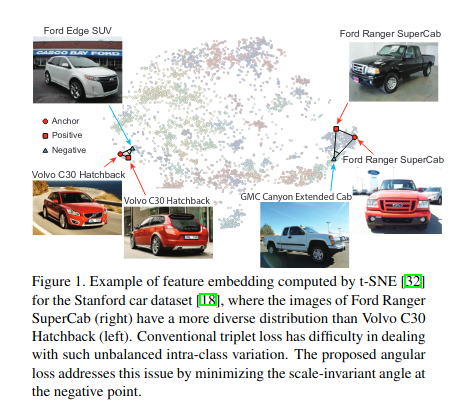
Combining these techniques helps to map semantically-related content to neighborhoods in an embedding space.
Finally, we can use simple candidate generation techniques like (approximate) nearest neighbors to recommend titles based on a historical interest indicated in a user’s watch history. Alternatively, we can use a ScaNN layer from tf-recommenders.
Results
Generating the top 10 most similar posters for sample queries, we find embeddings which transcend their genre labels to yield semantically cohesive neighborhoods.
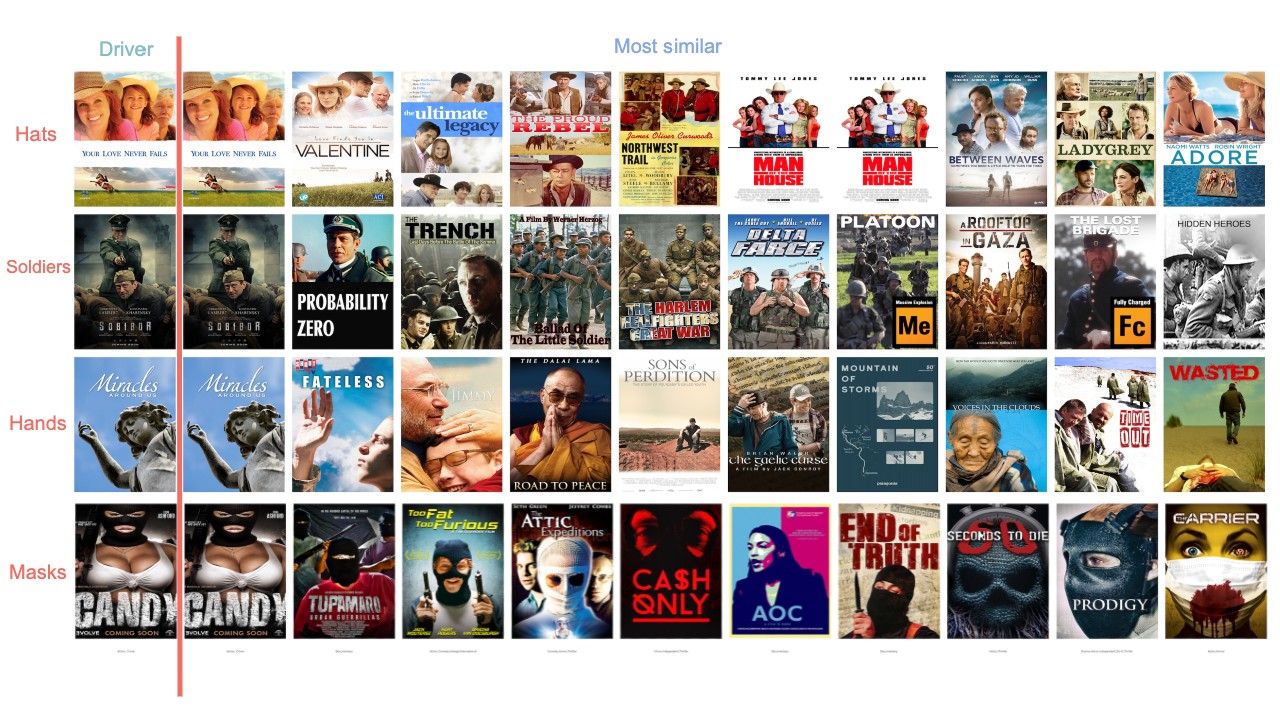
Similar to word2vec, we can mix stylistic elements of posters by finding images near the averaged embedding.

For more on the code, check out the repo!
Conclusion
Groups like Pinterest show that visual content-signals can be leveraged to help users discover relevant content.
By encoding semantic information presented in image content, we can more easily utilize the relatively abundant click through data to model user interests and behaviors to build more sophisticated recommender systems.
Though image classification has been shown to perform well for image retrieval and similarity, metric learning is easier than ever with Tensorflow’s TripletSemiHardLoss and more directly optimized for the task at hand.
Representation collapse poses a challenge in applying metric learning, whereby distinct inputs are mapped to the same output embedding by the model, ultimately failing to encode visual similarity. We find genre labeling of theatrical posters cheap and flexible while providing hard negatives to limit collapsed representations.