Lately, we’ve come to enjoy using the DepthAI OAK-D, which features an RGB camera with stereo depth, IMU, and Intel’s MyriadX VPU. Along with this powerful hardware combination, DepthAI provides a rich SDK to build your own embedded vision pipelines. Many projects are included to get you started.
These specs could help bring spatial AI to the SpecMirror where we can test representing human activities with pointcloud video.
The Data
First, we will generate training samples for activity recognition models like P4Transformer. This model uses pointcloud video input for a low-bandwidth feature which conveys geometric information.
Modifying this example, we write pointcloud data as .ply files with Open3D.
We begin with a toy dataset by recording clips performing activities like: walking, standing, drinking, waiving hand.

Recording in front of a simple background, we can apply Open3D’s plane segmentation for background removal.

It’s important to reduce outliers in preprocessing. Otherwise, training examples will have distorted aspect ratio after normalization. And so, we apply density based clustering to remove all but the largest cluster. Then we apply radial/statistical outlier removal to erode the point clouds further. A final clustering/filtering stage yields:

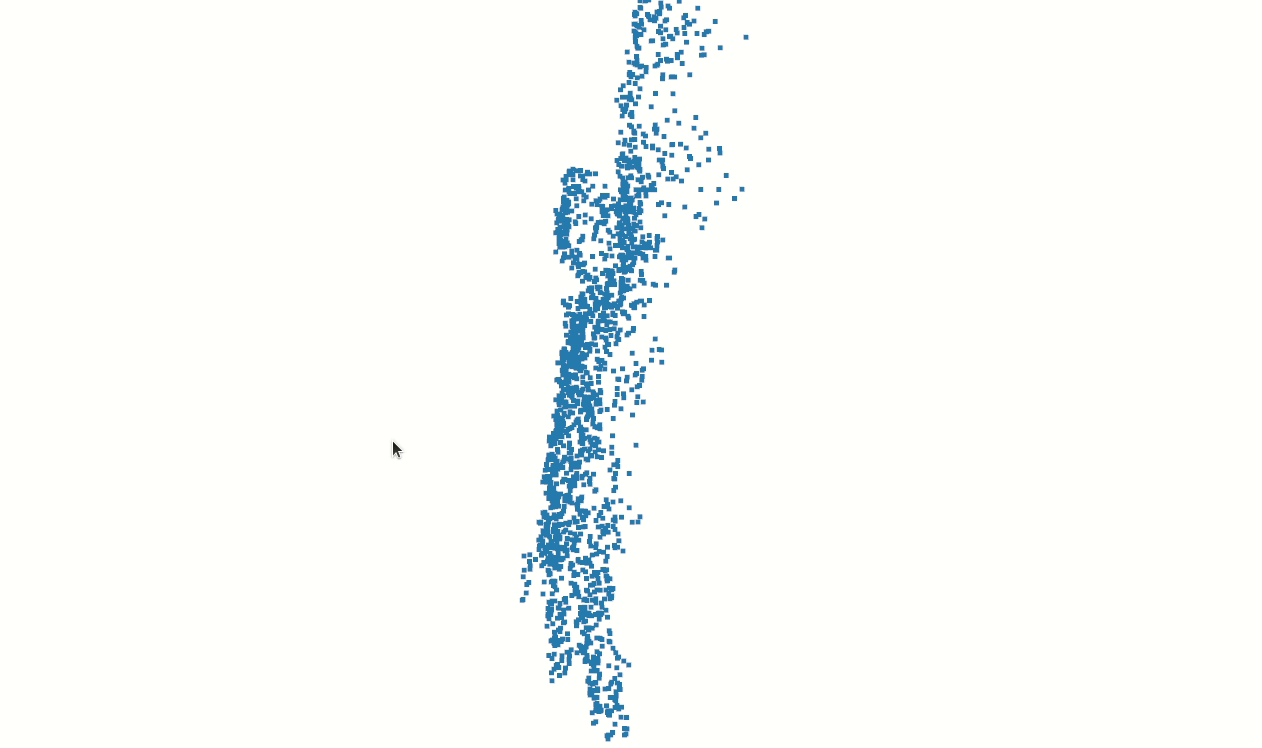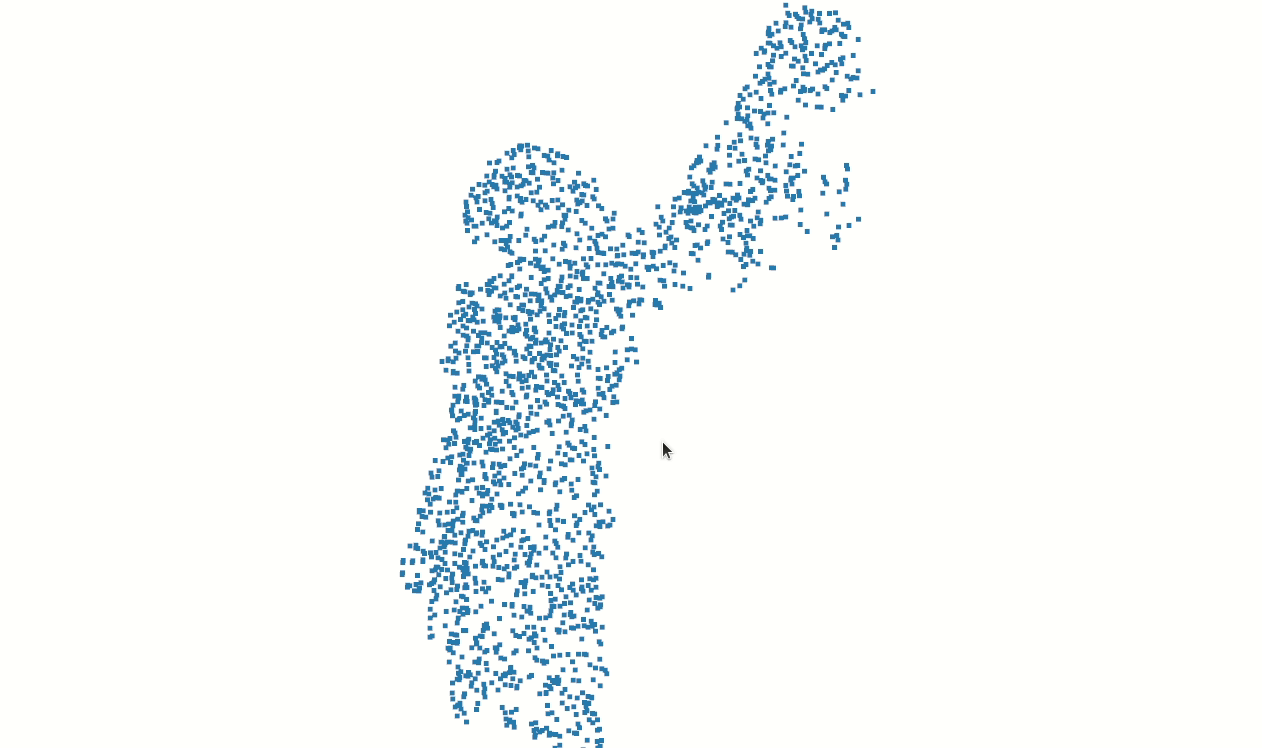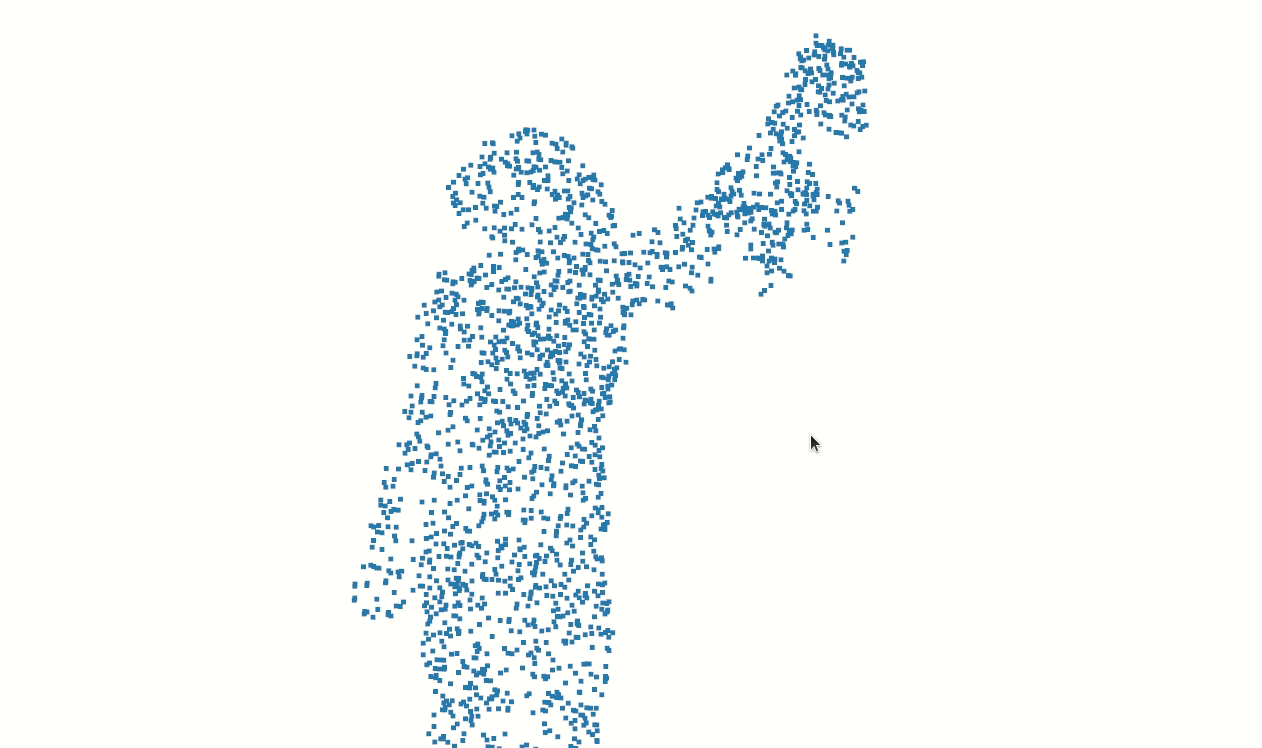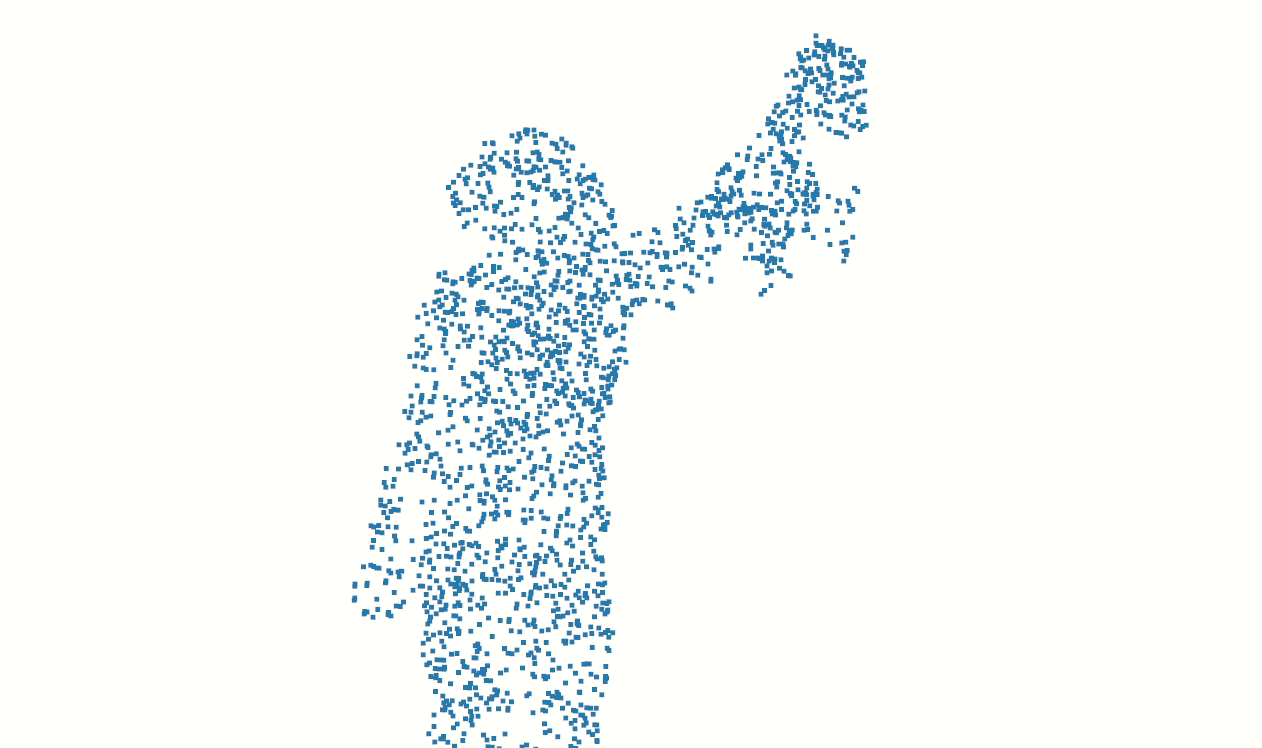
Finally, we have isolated the points associated with the subject.

By default P4Transformer samples 2048 points which gives a spatial resolution like the sample below.
Training
The P4Transformer repo uses specialized CUDA kernels for PointNet2. We’ve built and hosted a Docker image that contains all the requirements for training.
We have a toy dataset and have trained a model:
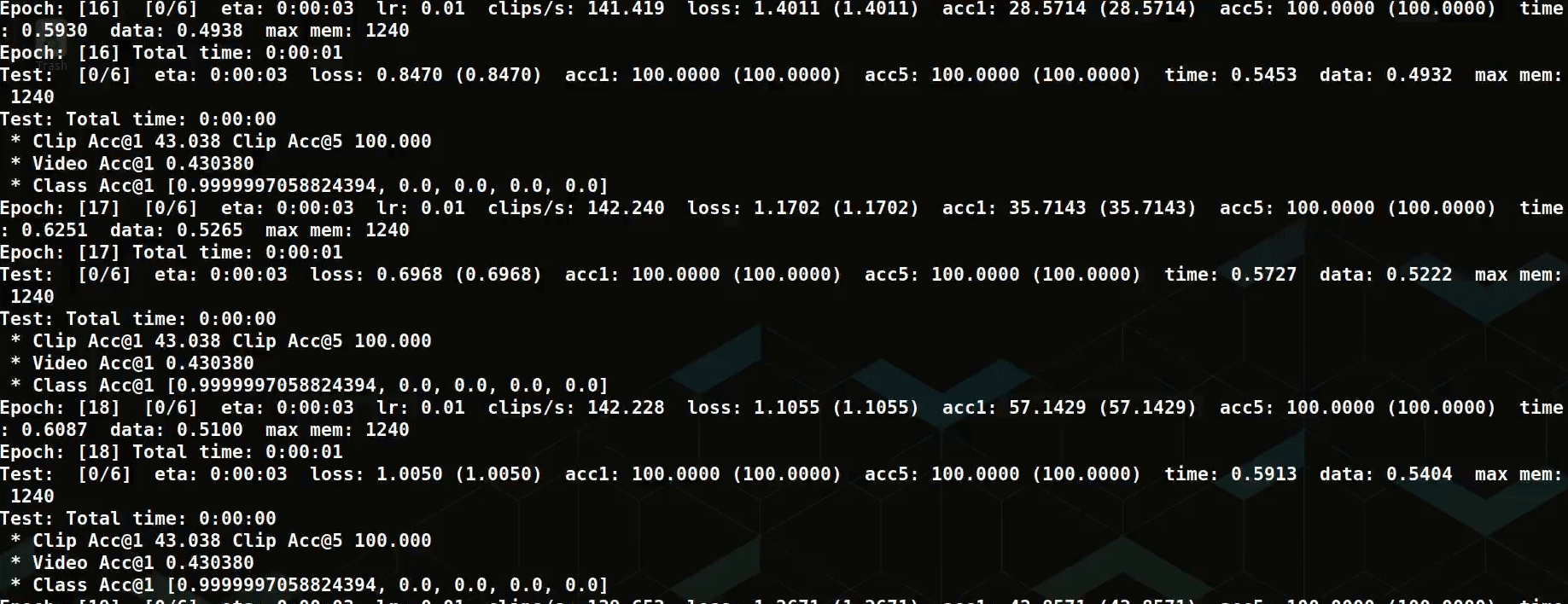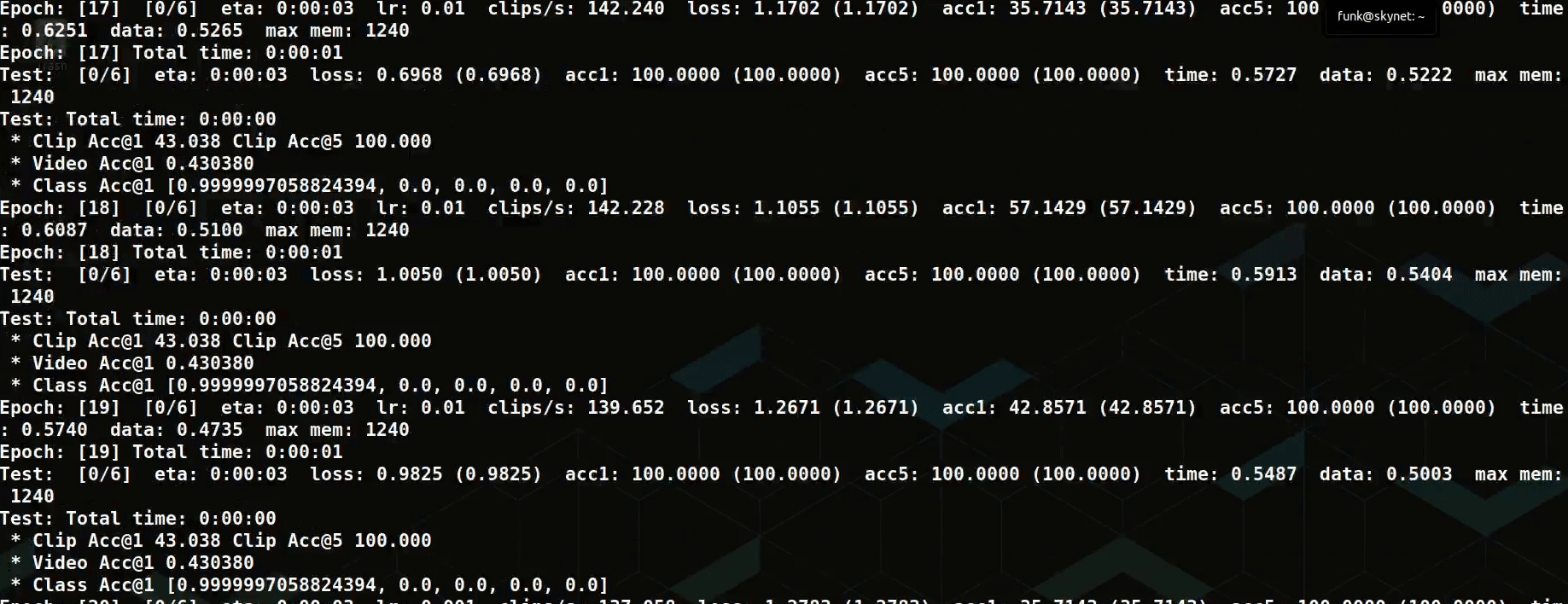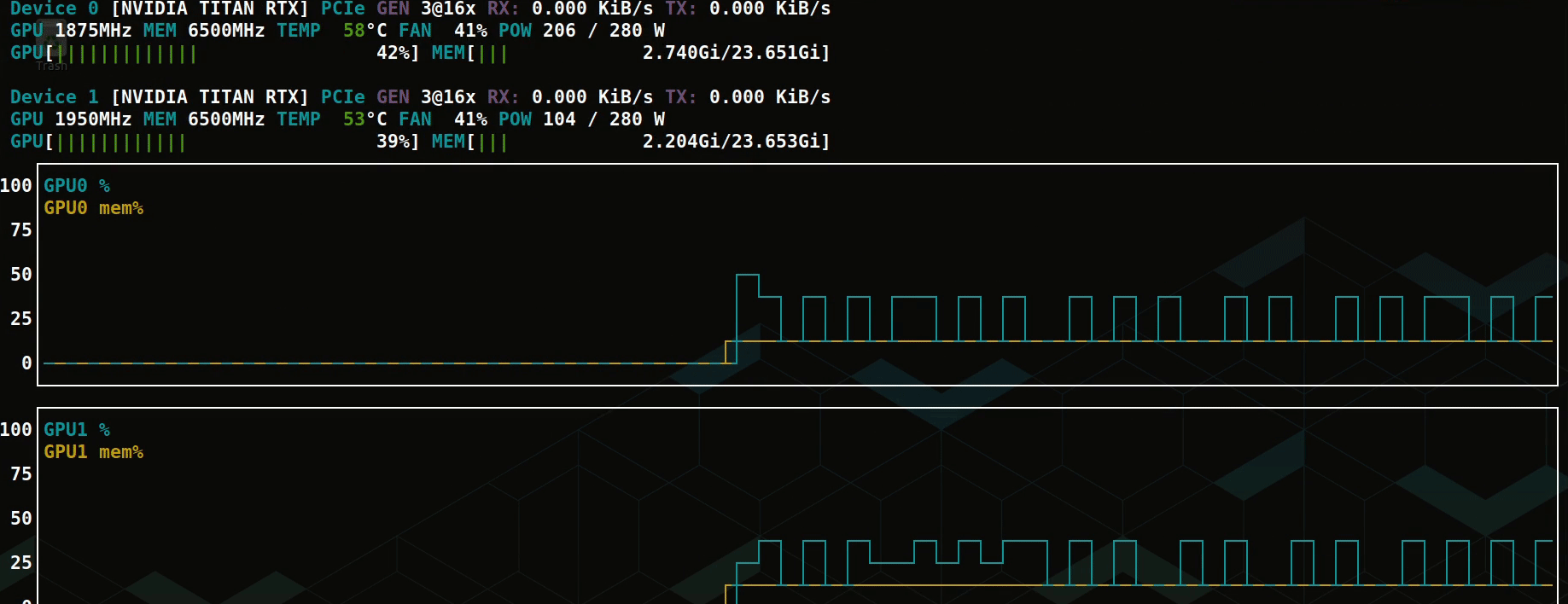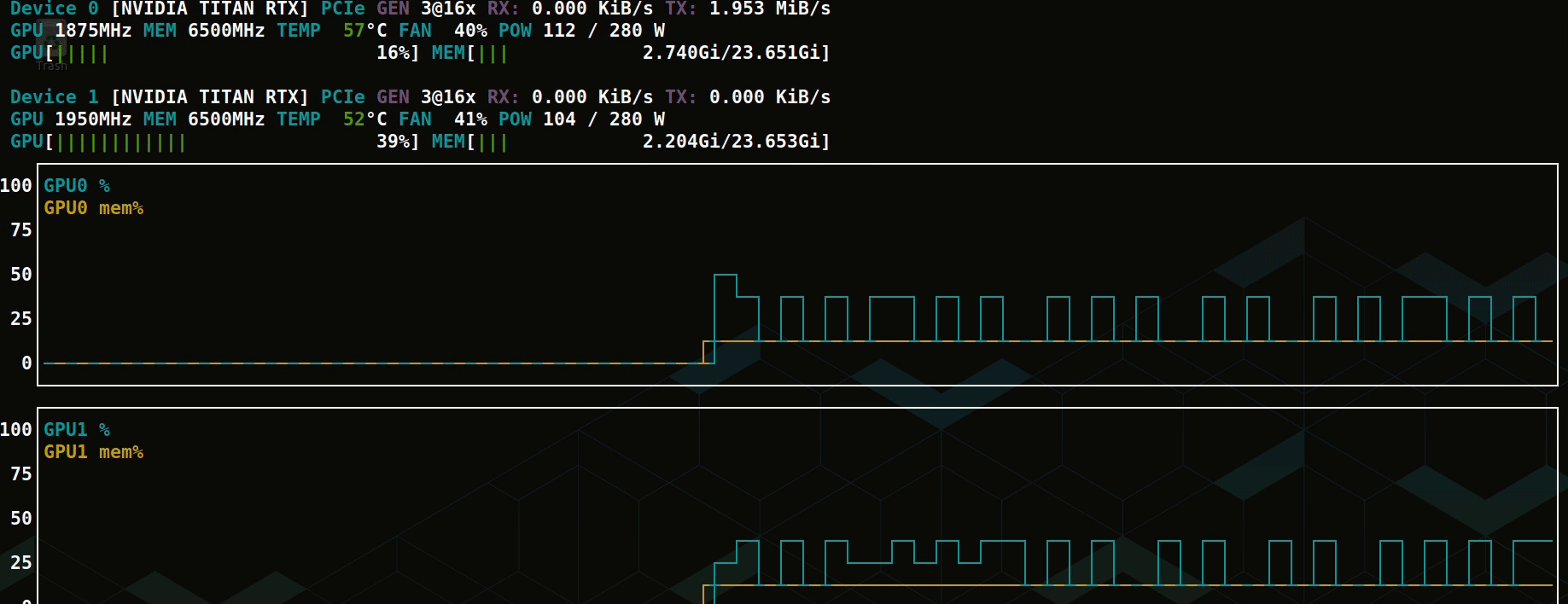
What’s Next?
We can add a semantic segmentation stage to our pipeline using this reference example:.
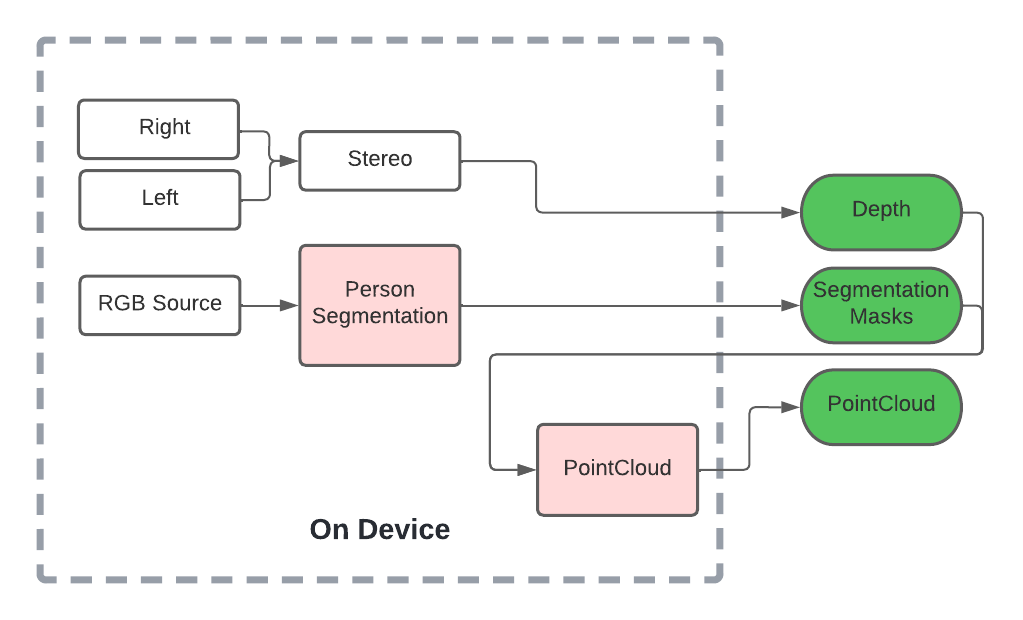
With pointcloud processing on the edge, we can buffer frames on our Jetson for SpecMirror’s activity recognition using P4Transformer, stay tuned!