Modern archeologists have been able to survey larger structures more precisely using remote sensing and photogrammetry.

More recently, researchers demonstrate applications of multi view stereo with networked embedded cameras to track geological disturbances.
In scenarios where visibility comes with high cost or saftey risk, the ability to quickly render high-fidelity reconstructions for offline analysis & review can be a powerful tool.
Advances in techniques like multi-view stereo and structure from motion have reduced the cost by alleviating dependence on more expensive sensors like lidar.
Generally, these methods track 2D image features using SIFT or superpoint across views or video sequences.
Combining matched features with a model for the camera, we can estimate its perspective before lifting 2D features in the image plane to 3D spatial coordinates.
The problem can be made tractable by applying constraints on temporal, geometric, and photometric consistency. Solutions can be made more robust by integrating additional information such as inertial sensor data.
Open source libraries like colmap greatly reduce the technical challenge to generating a reconstruction with high-level pipelines like automatic_reconstructor.

This tool shines in large scale reconstruction applications. In this case, one typically can batch process large volumes of high quality imagery along with good estimates of the intrinsic parameters of the cameras.
Researchers turn to neural networks to improve depth estimation by encoding scene priors while smoothing noisy input signals. Neural Disparity Refinement works by smoothing stereo depth in this way. Other researchers use sparse sfm features as a cheap supervisory signals to more efficiently learn nerf for scene view synthesis.
Efficient reconstruction is key for adapting to changing scene conditions. These researchers navigate quadrupedal robots across challenging terrains like stairwells.

Simplifying structural assumptions on scene geometry can also be applied in reconstruction. SparsePlanes recognizes that many indoor settings can be well approximated by a few intersecting planes.


PlanarRecon is part of a recent & exciting line of work which performs real-time 3D scene reconstruction using fast planar approximation to the scene. Here is a reconstruction of our living room.

For comparison, check out this grocery ailse:

By tracking and fusing planar segments, PlanarRecon is the fast linearized successor of NeuralRecon. For applications favoring accuracy over speed, NeuralRecon may be the preferred approach to reconstruction from posed monocular video.

Though these models were trained on ScanNet, the authors remarked of the decent performance for out-of-domain outdoor settings.

These tools make it easy to generate a high-fidelity texutured mesh of a scene for applications in AR/VR, robotics, synthetic data, and smart retail.
With semantic segmentation, we can decompose a scene, make edits, and render new perspectives:

Consider Amazon’s Go store where they can embed many cameras for scene reconstruction via MVS. Groups like Standard Cognition are competing in automated checkout by retrofitting shops similarly, prompting us to ponder new frontiers in rapid mapping…
Could you implement a similar solution from a cold-start i.e. with very limited prior knowledge? Imagine “pop up” scenes like a concert, a farmer’s market, or a circus.

Can we cheaply scan these scenes, deploy cameras with minimal configuration, and make inference about how humans are interacting in a loosely structured scene?
More broadly, shutting down operations for expensive calibration and mapping processes is not the way you want to begin an engagement.
Returning to the grocery store, we can try to decompose our scene reconstruction to track inventory.

Here, we show an unsupervised superpixel segmentation technique to extract regions of interest in our cluttered scene.

Visual artifacts like motion blur render template matching techniques brittle/unreliable. However, the following google image search experiment suggests we can match to known reference images by embedding similarity:
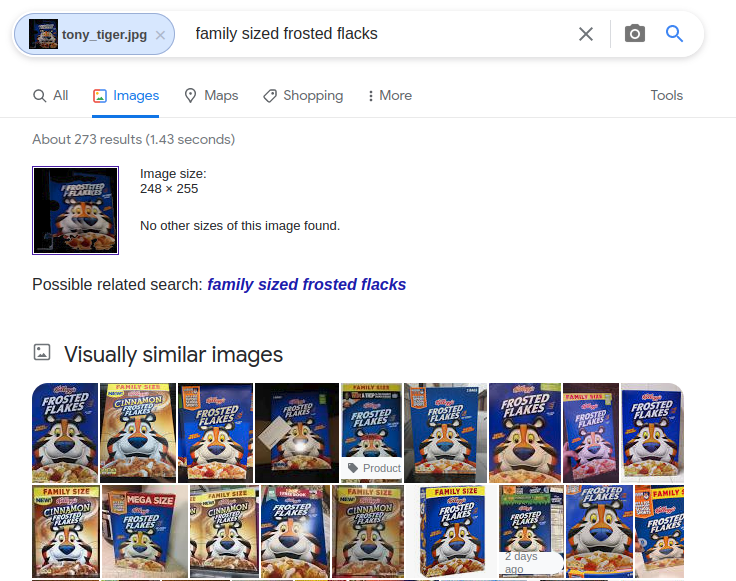
Provided fast reconstruction on a slowly varying scene, we can try object based localization and with enough GPU RAM, techniques like DROID-SLAM can be used in real-time.

What’s Next?
With an OAK camera, it is possible to re-architect NeuralRecon to run the Mnasnet feature extractors on-device. After syncing on a host device with GPU, the features can feed into NeuConNet, fused with camera pose for real-time reconstruction.
We’re also excited about applying scene reconstruction/decomposition for real2sim-sim2real and few shot learning with synthetic data.
We reviewed some exciting work in reconstruction, testing in our scenes and considering the speed accuracy tradeoffs as well as hardware architectures which can enable real-time applications.
With fast & accurate scene reconstruction, we can push the limits of 3d object detection and activity recognition.
We can develop visual inventory control using image matching with spatial search constraints by 3D localization along with data structures like rtrees.
Follow along for updates!