Introducing TF-Recommenders
Recently, Google open sourced a Keras API for building recommender systems called TF-Recommenders.
TF-Recommenders is flexible, making it easy to integrate heterogeneous signals like implicit ratings from user interactions, content embeddings, or real-time context info. This module also introduces losses specialized for ranking and retrieval which can be combined to benefit from multi-task learning. The developers emphasize the ease-of-use in research, as well as the robustness for deployment in web-scale applications.
In this blog, we demonstrate how easy it is to deploy a TFRS model using the popular Kubernetes platform for a highly-scalable recommender system.
Application deployment with Kubernetes
As a reference, we are using the multitask demo example featured in the TF-Recommenders repo.
This model generates user embeddings from:
- The
model.user_model()saved as a SavedModel
With a user embedding, we generate candidates with approximate nearest neighbors using an index of items.
- An Annoy index of the embeddings from
model.movie_model()
For more details on saving the model and annoy index, see our repo.
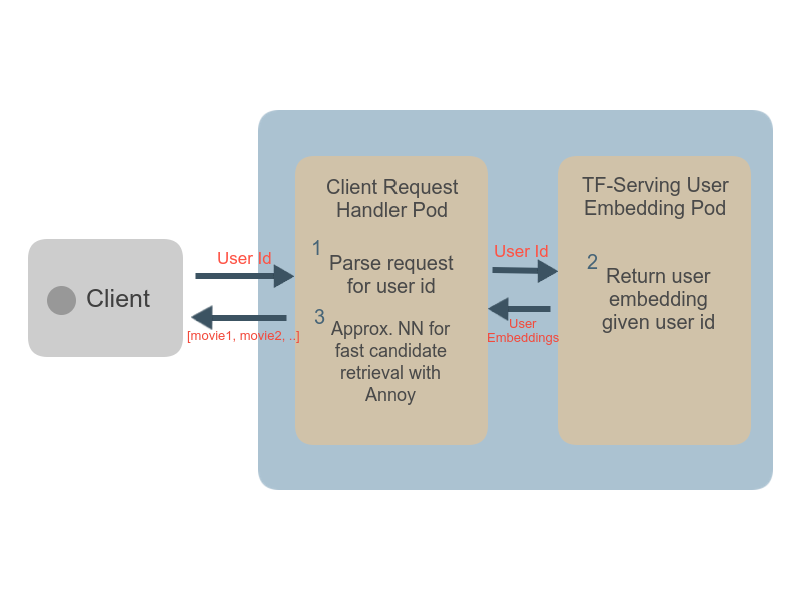
The deployment uses two pods, one for each process:
- Pod 1: serving the
model.user_model()using a TF-Serving Docker image - Pod 2: serving a Flask API app that gets a user_id as input and returns the top N recommendations using the AnnoyIndex of
movie.movie_model()embeddings and user embedding.
We begin testing our deployment locally with minikube.
$ minikube start
In a production environment, we use a container registry to store our Docker images but here we use locally built Docker images.
The minikube cluster can only find Docker images within its environment, so we configure the local environment to use the Docker daemon inside the minikube cluster.
$ eval $(minikube docker-env)
Next, we build the Docker images for each pod.
A simple Flask app works to:
- query our user model server for the user embedding
- return movie recommendations using the user embedding and indexed movie embeddings
We use the grpc example from the tensorflow serving repo to model how to query the user model server.
We also import a saved annoy index of our movie model embeddings and a dictionary that translates the annoy index to movie titles.
top_N = 10
embedding_dimension = 32
# Load annoy index
content_index = AnnoyIndex(embedding_dimension, "dot")
content_index.load('content_embedding.tree')
# load index to movie mapping
with open('content_index_to_movie.p', 'rb') as fp:
content_index_to_movie = pickle.load(fp)
def get_user_embedding(user_id):
"""
Helper function to ping user model server to return user embeddings
input: user id
output: 32-dim user embedding
"""
channel = grpc.insecure_channel(FLAGS.server)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
# Send request
# See prediction_service.proto for gRPC request/response details.
request = predict_pb2.PredictRequest()
request.model_spec.name = 'user_model'
request.model_spec.signature_name = 'serving_default'
request.inputs['string_lookup_1_input'].CopyFrom(
tf.make_tensor_proto(user_id, shape=[1]))
result = stub.Predict(request, 10.0) # 10 secs timeout
embedding = np.array(result.outputs["embedding_1"].float_val)
return tf.convert_to_tensor(embedding)
Then, we set up our endpoint that takes a user id and returns a list of the top_N recommended movies.
class Recommender(Resource):
"""
Flask API that returns a list of top_N recommended titles for a user id
input: user id
output: list of top_N recommended movie titles
"""
def get(self, user_id):
user_recs = {"user_id": [], "recommendations": []}
user = tf.convert_to_tensor(user_id, dtype="string")
query_embedding = get_user_embedding(user)
# get nearest neighbor of user embedding from indexed movie embeddings
candidates = content_index.get_nns_by_vector(query_embedding, top_N)
candidates = [content_index_to_movie[x].decode("utf-8") \
for x in candidates] # translate from annoy index to movie title
user_recs["user_id"].append(user.numpy().decode("utf-8"))
user_recs["recommendations"].append(candidates)
return user_recs
Now we want to build the docker image for our Flask app. See our Dockerfile.
$ docker build -f Dockerfile -t recommender-app:latest .
We use TFServing as our base image and build a with our user model. More detailed instructions here.
Now, each pod has a deployment configuration and a service configuration.
The deployment section references the docker images we’ve built locally. The service section configures how the apps will interface with each other and with outside requests.
The TFServing pod should only be accessible to the Flask app, which is in the same cluster. Therefore, we can configure it to expose the ClusterIP port.
In contrast, the Flask app serves requests to clients outside of the cluster, so we assign an external ip and configure the Flask app to expose the LoadBalancer port. This also allows for flexible scaling of the pod to handle more requests.
Deploying the full app is simple using kubectl with our minikube cluster. We can deploy both pods with:
$ kubectl apply -f recommender-app.yaml
$ kubectl apply -f user-model.yaml
We can check their statuses with:
$ kubectl get deployments
>NAME READY UP-TO-DATE AVAILABLE AGE
recommender-app 1/1 1 1 1m
user-model 1/1 1 1 1m
And we can see the services running with:
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 10m
recommender-service LoadBalancer 10.105.151.169 <pending> 6000:30242/TCP 1m
user-model-service ClusterIP 10.96.196.146 <none> 8500/TCP 1m
While deploying with minikube locally, we need to expose the external ip for the recommender-service shown above. Simply run:
$ minikube service recommender-service
|-----------|---------------------|-------------|---------------------------|
| NAMESPACE | NAME | TARGET PORT | URL |
|-----------|---------------------|-------------|---------------------------|
| default | recommender-service | 6000 | http://192.168.49.2:30242 |
|-----------|---------------------|-------------|---------------------------|
Which returns a url we can curl! Now curl the Flask API app like so:
$ curl 192.168.49.2:30242/recommend/1 # get recommendations for user 1
And the server will return something like this:
{
"user_id": [
"1"
],
"recommendations": [
[
'Toy Story (1995)',
'Jumanji (1995)',
...
]
]
}
After successfully modeling our Kubernetes deployment locally, we can clean up.
$ kubectl delete services recommender-service user-model-service
$ kubectl delete deployments recommender-app user-model
$ minikube stop
$ minikube delete
With tools like Kubernetes and libraries like TF-Recommenders and Annoy, the process of building fast recommender systems is simplified. The TF-Recommenders library simplifies the integration of various signals for making recommendations using neural networks.