Check out remyx.ai
![]()
Why do we care about ML in product?
As you’re reading this, one might assume that you are familiar with machine learning (ML) concepts.
But since we aim to reach a broad, ML-curious developer audience with this post, let us simply frame our interest in ML-based product features which help us to make decisions using cheaper data.
The case for custom ML
Many practical machine learning tasks come down to differentiating between only a few object categories in a constrained environment. Despite this reality, vision models are typically evaluated based on accuracy in predicting 1000+ category benchmark datasets like ImageNet.
Often the dataset full of samples relevant to your perception task doesn’t exist. Engineers are limited in demonstrating what is possible by using only pretrained models.
Once you have training samples, the practice of transfer learning requires a number of decisions around model selection and the training regiment to achieve an optimal speed-accuracy tradeoff for the task at hand.
Building inference-optimized model artifacts for the target deployment environment presents additional challenges. And of course, the model is a relatively small component of a more complex system to serve inference.
Finally, we anticipate the business need to specialize models to each customer for the best performance.
ML to Make ML
The term “autoML” evokes the possibility of simply describing a ML model you want to generate programmatically.
Though it’s often cited that up to 80% of a data scientist’s efforts are spent in data preparation, most AutoML tools work by orchestrating hyperparameter optimization over a family of models.
Some autoML platforms support a manual data annotation workflow while others feature the ability to generate the code behind the optimal model to adapt into your training/serving infrastructure.
However, no existing autoML product comes close to a no-code or automated workflow inspired by the term.
Making Data to make ML
An entire ecosystem of solutions have cropped up to support access to data structured for model training. Depending on your budget, you can pay for a license or a data labeling service or spend the time building similar systems.
But recent progress in generative AI has us bullish on algorithmic approaches as image and text generators are becoming sufficiently realistic, and crucially, controllable.

Even few-shot, instance-level predictions are possible using techniques like textual inversion/dreambooth, albeit at considerable compute costs.
Making Data Cheap
With the knowledge that we can generate custom datasets on-the-fly using diffusion, we can begin to optimize for larger batches of lower resolution images appropriate for training vision models.
Additionally, we understand the overlap of tasks amongst customers and can optimize our data curation strategies to serve those applications.
Finally, we recognize that we can start training faster by investing in the image retrieval infrastructure to quickly query custom training datasets.
Taking a Stance
By implementing a more opinionated autoML, we can create a better experience for our users.
Our multi-modal data indexing and generation strategies allow us to expose sophisticated transfer learning recipes through a no-code UI.
We abstract the complexities of model design behind convenient “t-shirt” sizing options meant to express the inherent tradeoffs in speed v. accuracy.
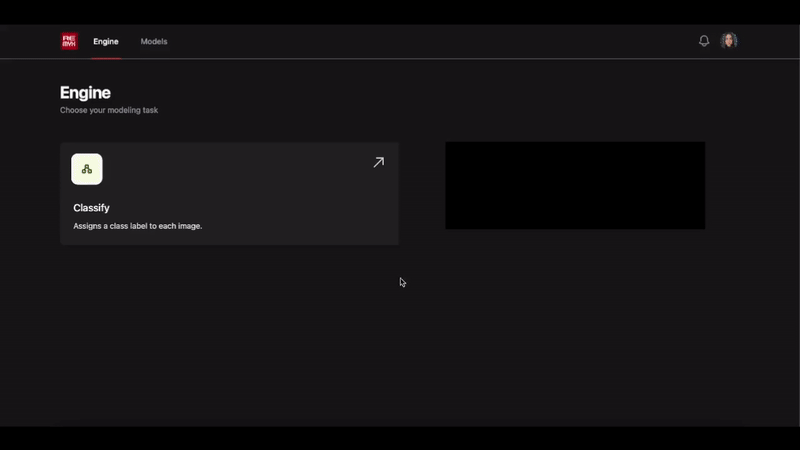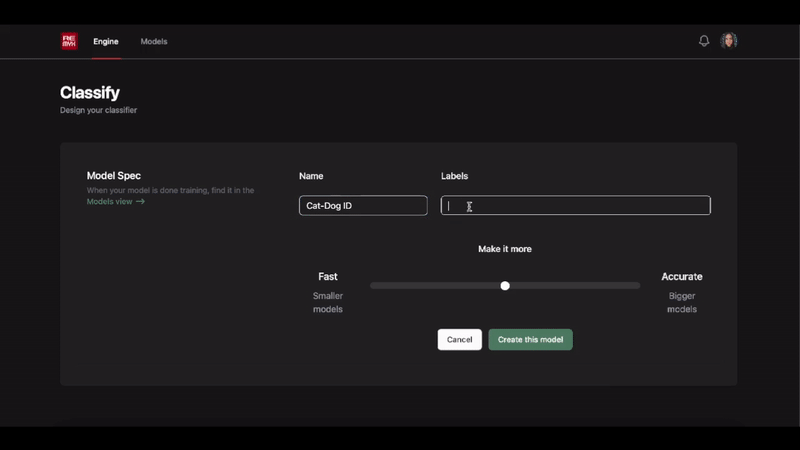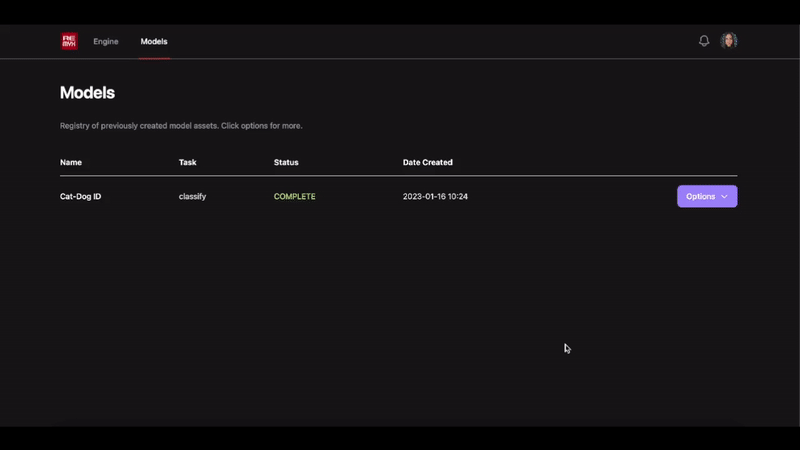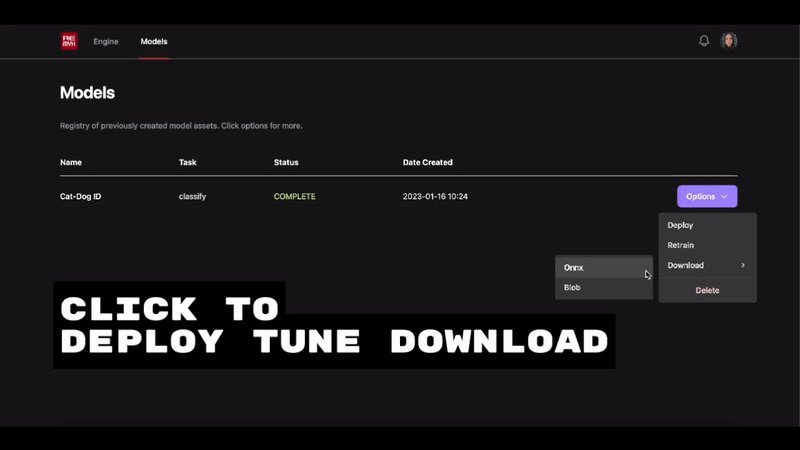
Text to Classifier/Detector
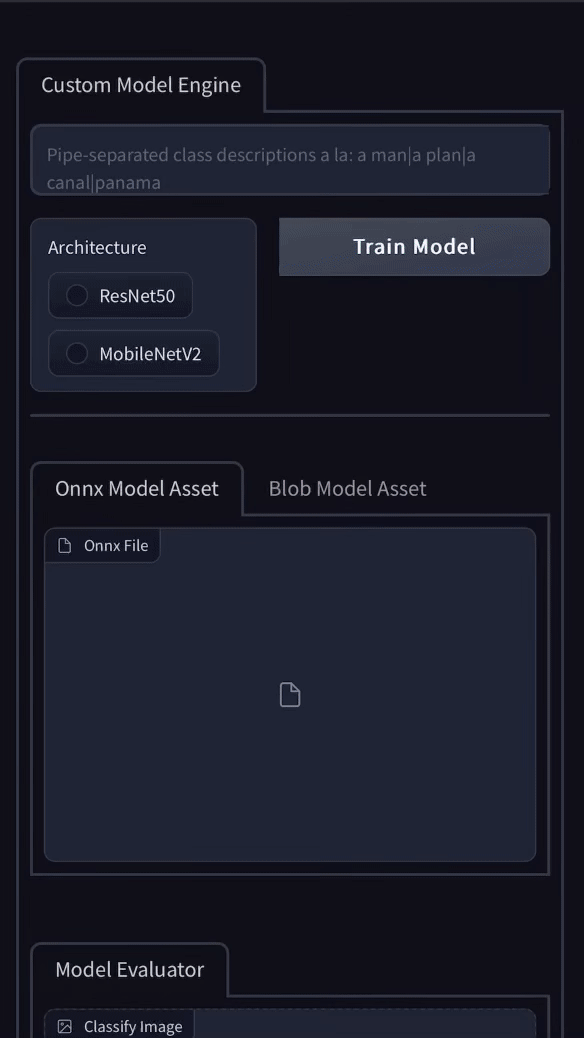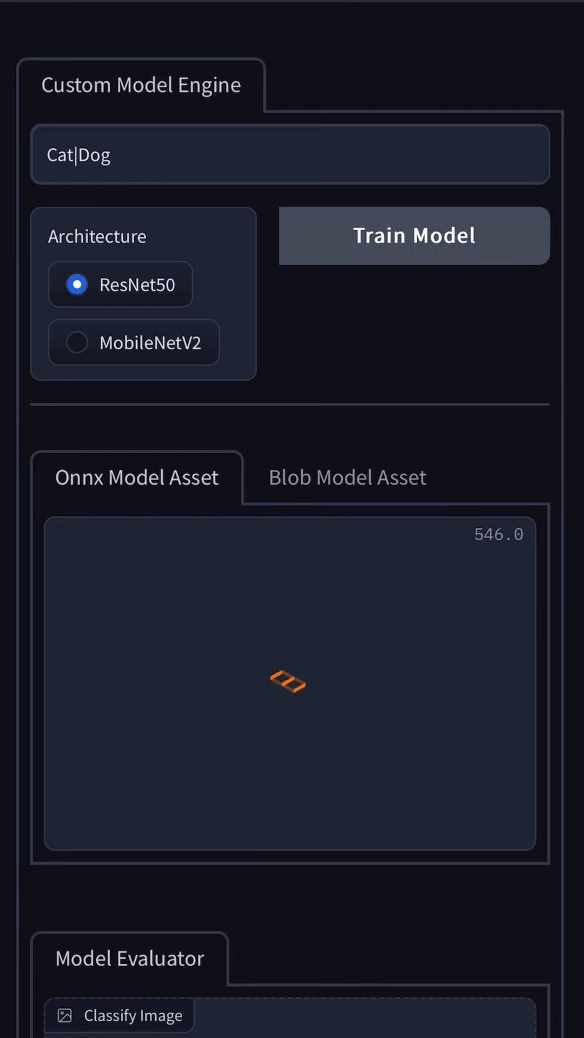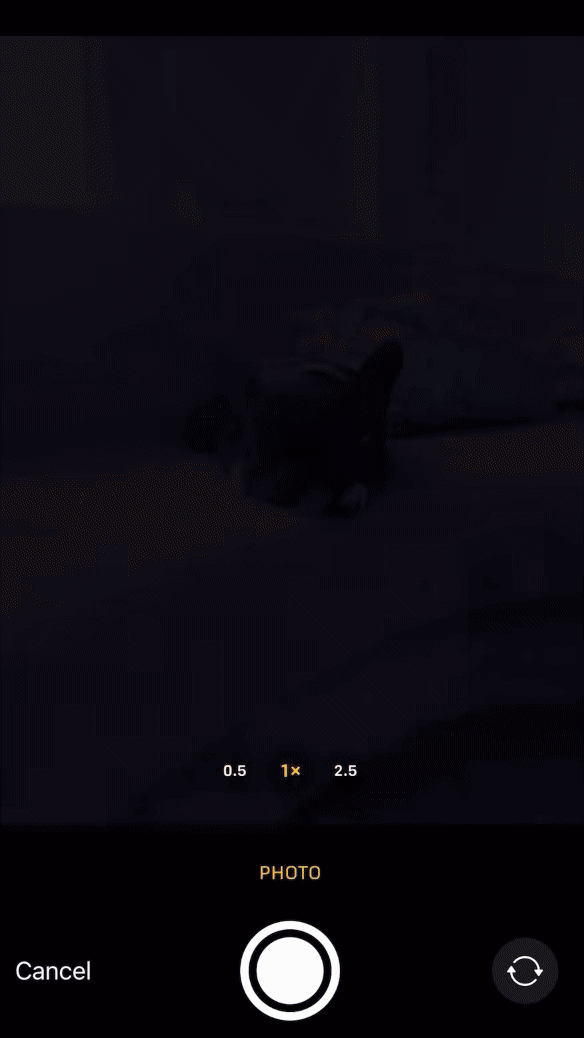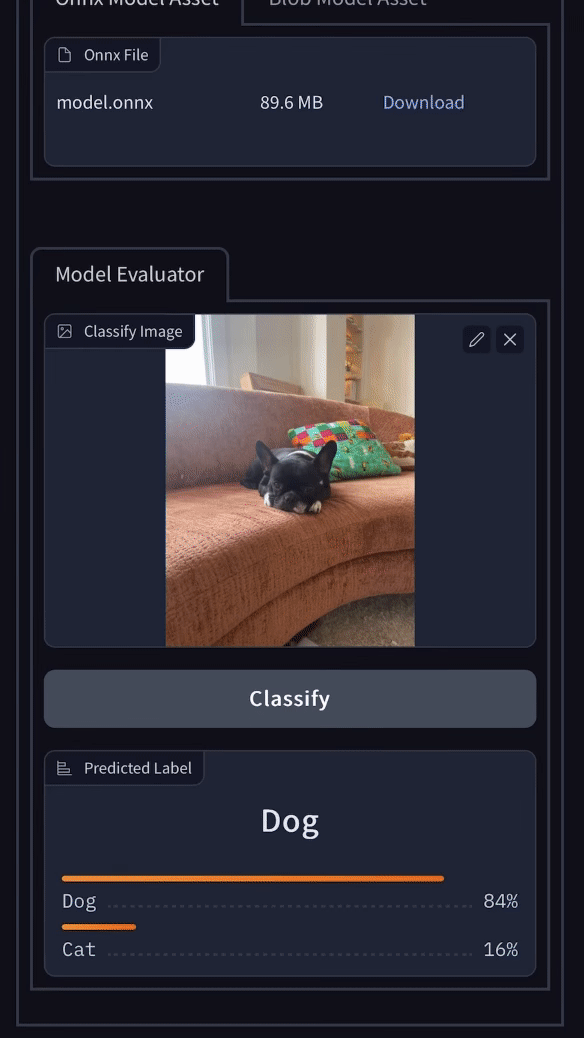
What started as a gradio demo showcasing the simplest workflow to build custom computer vision models has evolved into the Remyx Model Engine.
Having prototyped a tool we’re excited to use, we are developing a state of the art autoML pipeline to enable anyone to train models from a simple specification.
Launch
In the short time since then, we’ve learned much from the indie hacker community to quickly stand up our infrastructure.
We’d love to invite you to join the waitlist and follow our progress in delivering the smoothest model training experience at Remyx.ai.
