Some of our earliest work applying ML to video was done in the context of prototyping IoT products like YogAI.
A couple years ago, we described a more generalized pipeline called ActionAI.
ActionAI was designed to streamline prototyping IoT products using lightweight activity recognition pipelines on devices like NVIDIA’s Jetson Nano or the Coral Dev Board.
Since then, NVIDIA has introduced action recognition modules into their Deepstream SDK. They model a classifier using 3D convolutional kernels over the space-time volume of normalized regions of interest, batched over a k-window in time.
In fact, many SOTA results in video understanding and activity recognition employ 3D convolution or larger multi-stream network architectures.

More recently, researchers adapt Vision Transformers (ViT) to this task and some work has progressed from the task of recognition to anticipation.
In prototyping IoT products featuring human-computer interactions with ActionAI, we found the rich and highly localized context of pose estimation model inference results helpful.
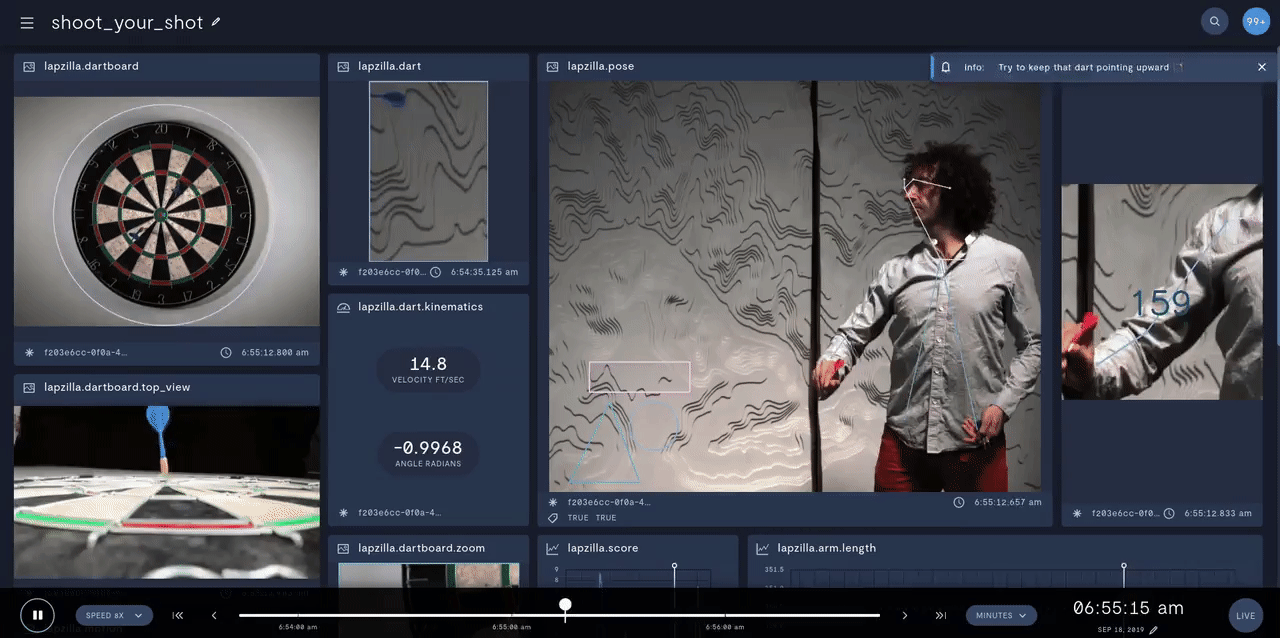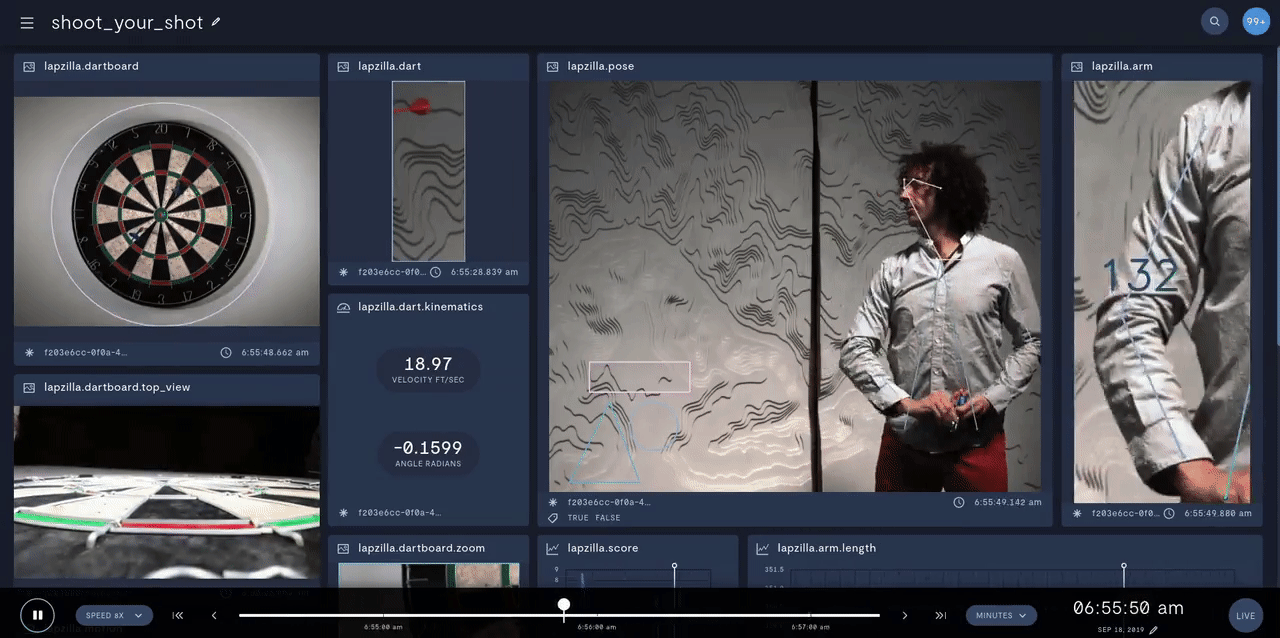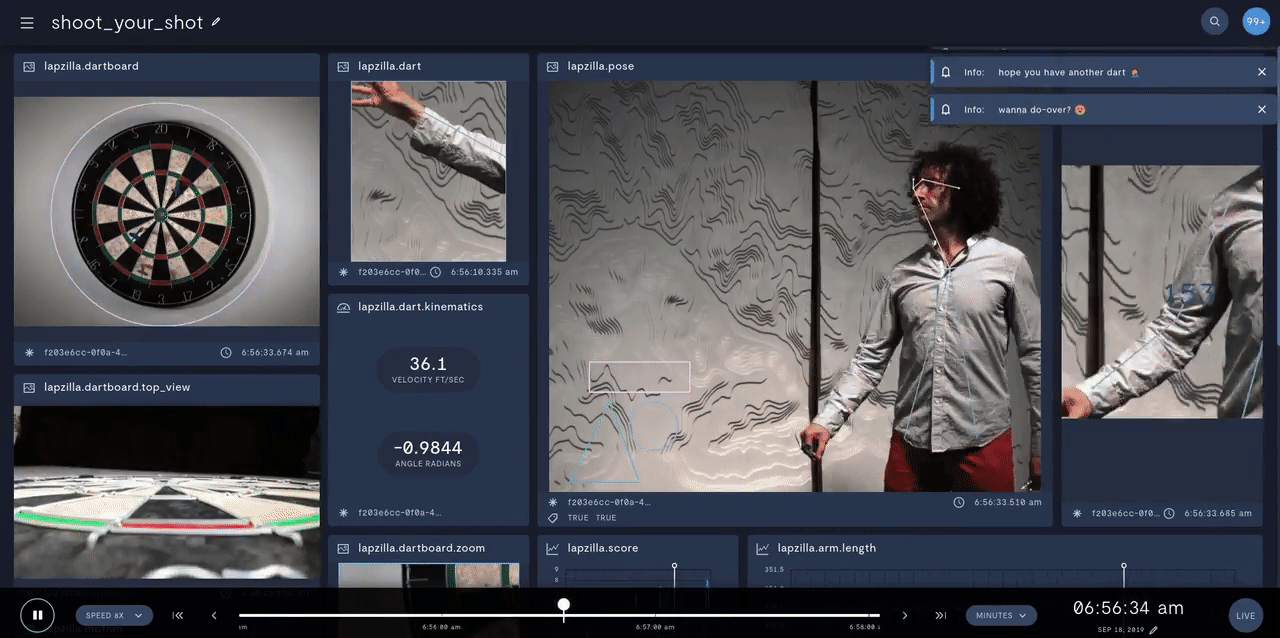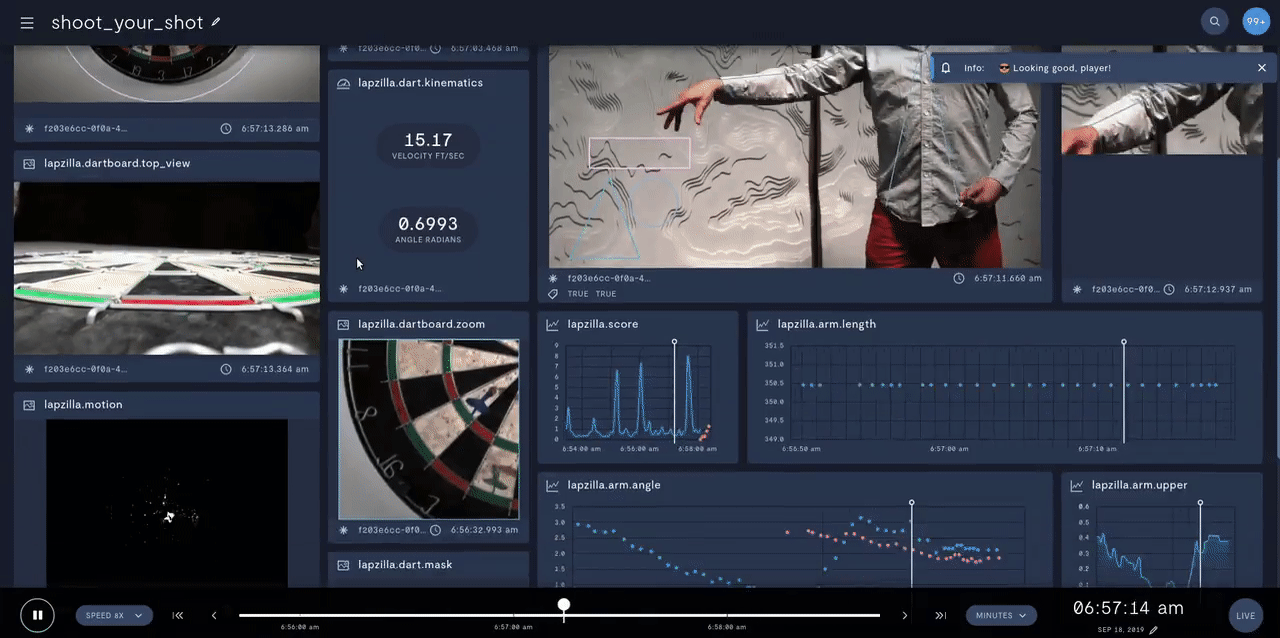
Applying Keypoint Detectors as fixed feature extractors also helped to project our high-bandwidth image input to low-dimensional features. From there, we can optimize sequential models to classify motion thereby limiting the capacity of our model to overfit to visual characteristics of people in motion.

Over this timeline, we have also been exploring related applications of human-centric video analytics pipelines for the purposes of deepfake detection:

As well as motion transfer, here with two-person transfer of a fight scene using kali sticks:

We’ve explored adapting ActionAI to the use of hand keypoints, face keypoints, and face embeddings but we have also been keen to generalize beyond these readily available models.

To those ends, we have been exploring first-order motion models (FOMM) and its related corpus of work. In our experiments generating content, we were impressed by the ability to apply these models across domain.

This impressive success in self-supervised learning of keypoint detectors for arbitrary objects led us to ask “What else could we do with few-shot video understanding by generalizing ActionAI pipeline ideas through the use of these keypoint detectors?”
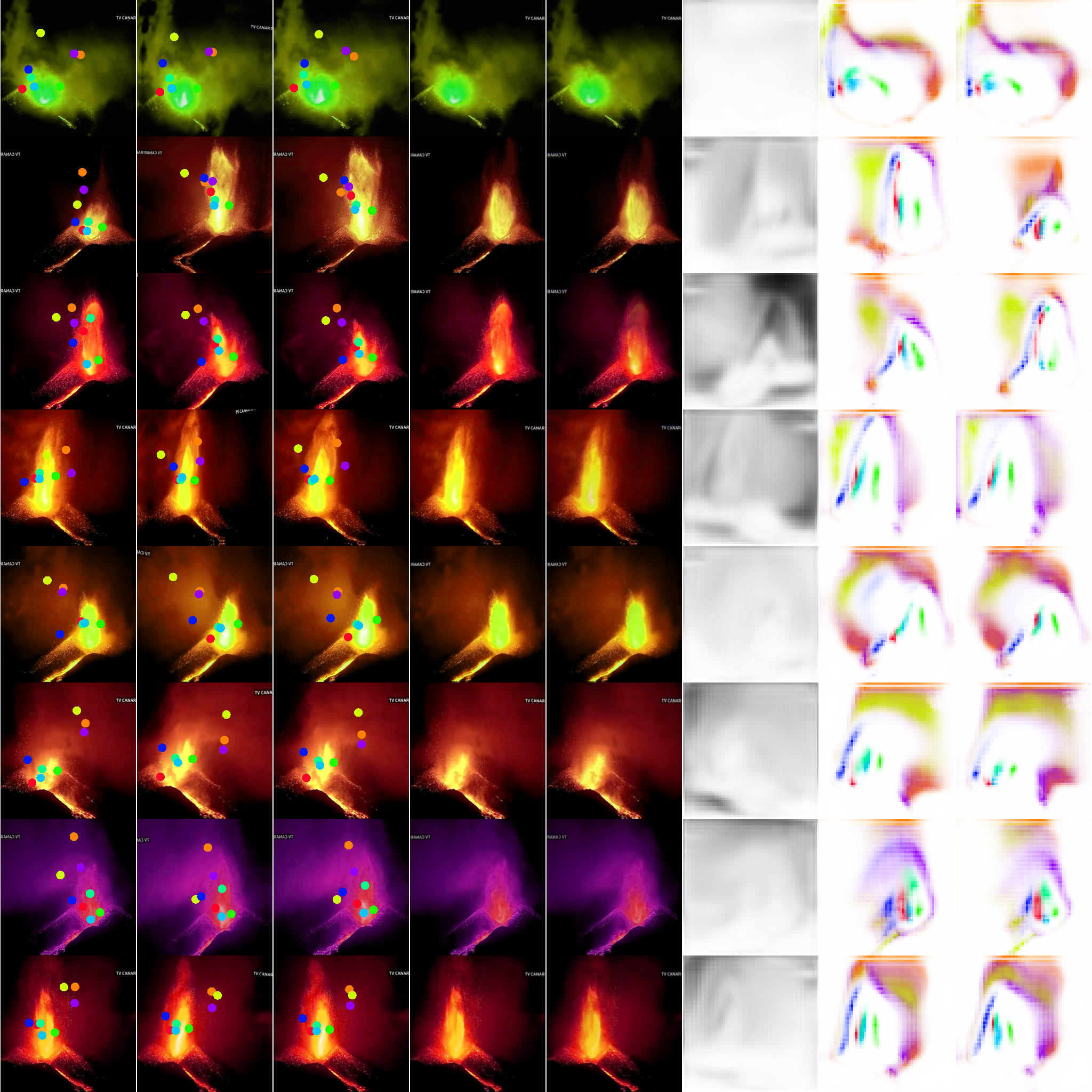
With a sample youtube video, we can characterize the motion of many object categories using self-supervised learning. Here we drive a synthesized image which happens to look like a volcanic eruption via articulated animation.

For many animated objects of interest, a mode of activity can be characterized by little more than motion and frequency over gross spatial and temporal scales with respect to camera’s field-of-view. We appreciate the potential to accelerate science and especially the analysis of complex biological behaviors under controlled studies by bootstrapping from relatively little training data.
Inferring modes of activity this way can be insufficient for video understanding, where the context of object-object interactions becomes relevant. Nonetheless, for many practical applications, a structured pipeline using detection & tracking will facilitate the extraction of additional cues through secondary models with prediction cascades.
Along those lines, we were recently introduced to the work in MovieGraphs, which endows richly annotated video with graph structure to perform video understanding. In application like film analysis, we may expect the expensive feature extraction is justified by recognizing its amortization over a lifetime of repeated consumption for human entertainment.

We believe graphs can be efficient in modeling complex interactions over space and time through pipelines like ActionAI, but we also want to emphasize real-time performance on resource-limited edge hardware.
Looking back at ActionAI, we realize it has been our most popular project and facilitated many related applications for us. But ActionAI has potential for much more than a repo documenting this collection of early AIoT prototypes.
In fact, this project has helped us gain attention and partnerships with the biggest groups in tech as they adopt related techniques in video understanding and perception.
But we believe ActionAI has the potential to accelerate these use cases in the same way projects like face_recognition and dlib have served users of those libraries.
As discussed above, we have many directions to consider but we aim to lean into lightweight and robust video pipelines. For starters, we might consider additional reductions to the training pipeline for these region predictors.
Consider joining the ActionAI Gitter where we can make this conversation dynamic!