This year marks a sharp increase in the use of streaming services.
Many platforms use video posters as the main representation of content to watch.
Naturally, the visual representation strongly influences a user’s propensity to watch the title. In fact, posters are designed to signal theme, genre and era.

There are many theories on how poster elements can convey an emotion or capture attention.
Netflix conducted a UX study, using eye tracking to find that 91% of titles are rejected after roughly 1 second of view time.
Here, we consider content-based recommendations which are visually-aware, by developing models for learning movie poster similarity.

Genre information and Weak Labeling
Genre information can be signaled in poster design through low-level information like color distribution as well as higher-level structural and semantic signals. While it is easy to align posters with the title’s genres to frame a learning task, we ultimately want to derive embeddings which transcend genre similarity while reducing the semantic gap.
Metric Learning
Some approaches/researchers consider a surrogate task of using the embeddings of the penultimate layer of a multilabel classifier as a representation for movie posters.
However, this recently open-sourced module makes it easy to frame a metric learning task using genre as weak labels. This makes it easy to carry out the sampling and implementing a margin-based loss more directly optimized for the task of measuring image similarity.
Additional Techniques
Movie posters are relatively complex compared to some image datasets like MNIST or FashionMNIST.

In many ways, movie posters are more similar to datasets like ImageNet, so we apply transfer learning from base networks pre-trained on ImageNet.
Characterizing the intrinsic dimensionality of our movie poster dataset can be made more precise using entropy measures like these autonomous perception researchers.
Ultimately, we expect higher capacity base network architectures to help.
We use the angular loss and follow the guidance of these researchers to tune the margin parameter for the dataset.
These techniques combined help in mapping semantically related content to nearby points in an embedding space.
Now, we can use simple recommendation techniques like (approximate) nearest neighbors to generate candidate movies based on a user’s interest in other titles from their watch history.
Results
Generating the top 10 most similar posters to a handful of driver examples shows how the embeddings are able to encode features that transcend their genre labels.
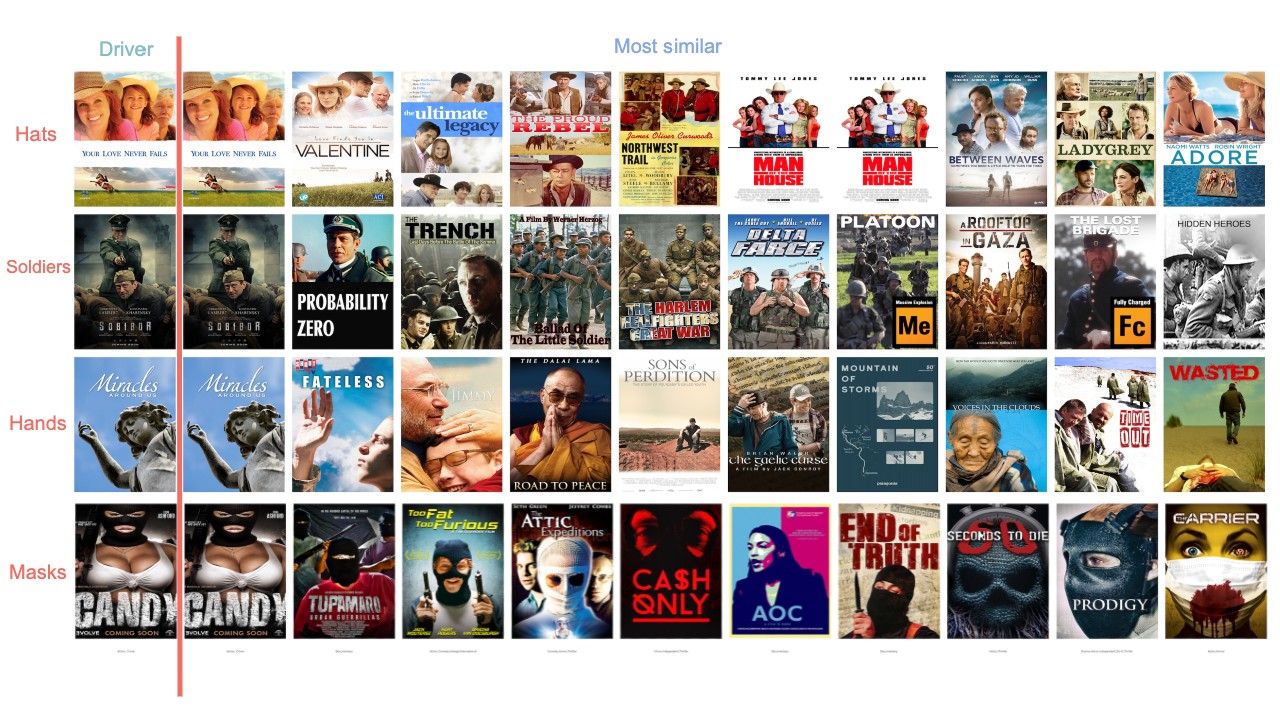
For more on the code, check out the repo!
Models like these can be used to exploit the bias a user may have towards clicking or viewing particular visual content. This demo underscores the importance of framing the best learning task for the objective.