Convolutional Neural Networks have been a boon to the computer vision community. Deep learning from high-bandwidth image/video datasets can be computationally and statistically much more efficient using the inductive bias of strong locality. This streamlines inference over big datasets or on resource-limited hardware.
To model sequential dependence in short sequences of low-dimensional data, we have often used LSTMs. However, researchers have recently found success adapting Transformer architectures to learn from image and video, both applications traditionally dominated by CNNs.
Vaswani et al’s pioneering work in machine translation introduced the Transformer, which utilizes attention mechanisms rather than recurrent or convolutional layers while encoding sequential structure through sinusoidal positional embeddings. Transformers would pave the way for many advances in NLP, most notably influencing the design of BERT.
Image and video data decoded into arrays admit sequential/grid representations. Video is generally recorded at frame rates sufficient to spatially resolve objects of interest, implying some degree of local spatial smoothness in image and video.
The space-time locality of convolutional kernels helps us to efficiently exploit this regularity to learn models with low parameter counts. Furthermore, sharing kernel weights over sliding windows combined with pooling helps to impose translation equivariance, a symmetry we expect to observe for many labeled datasets.
By comparison, self-attention in transformers is burdened by time & space complexity quadratic in the length of the input sequence. Despite this bottleneck, the model offers the capacity to learn from large-scale spatial interactions, spurring efforts to design more efficient transformers.
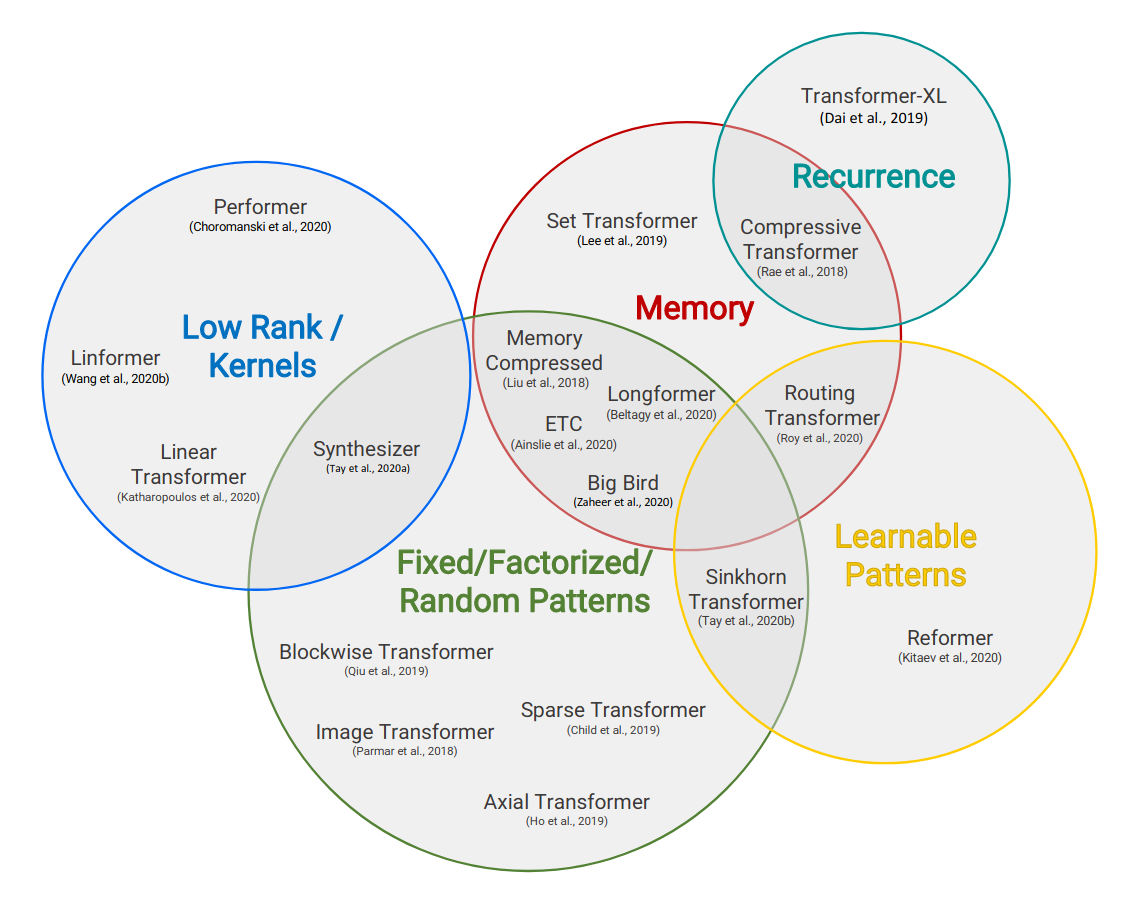
Google researchers describe a taxonomy of transformer variants, distinguished by the strategy used to sparsify attention.
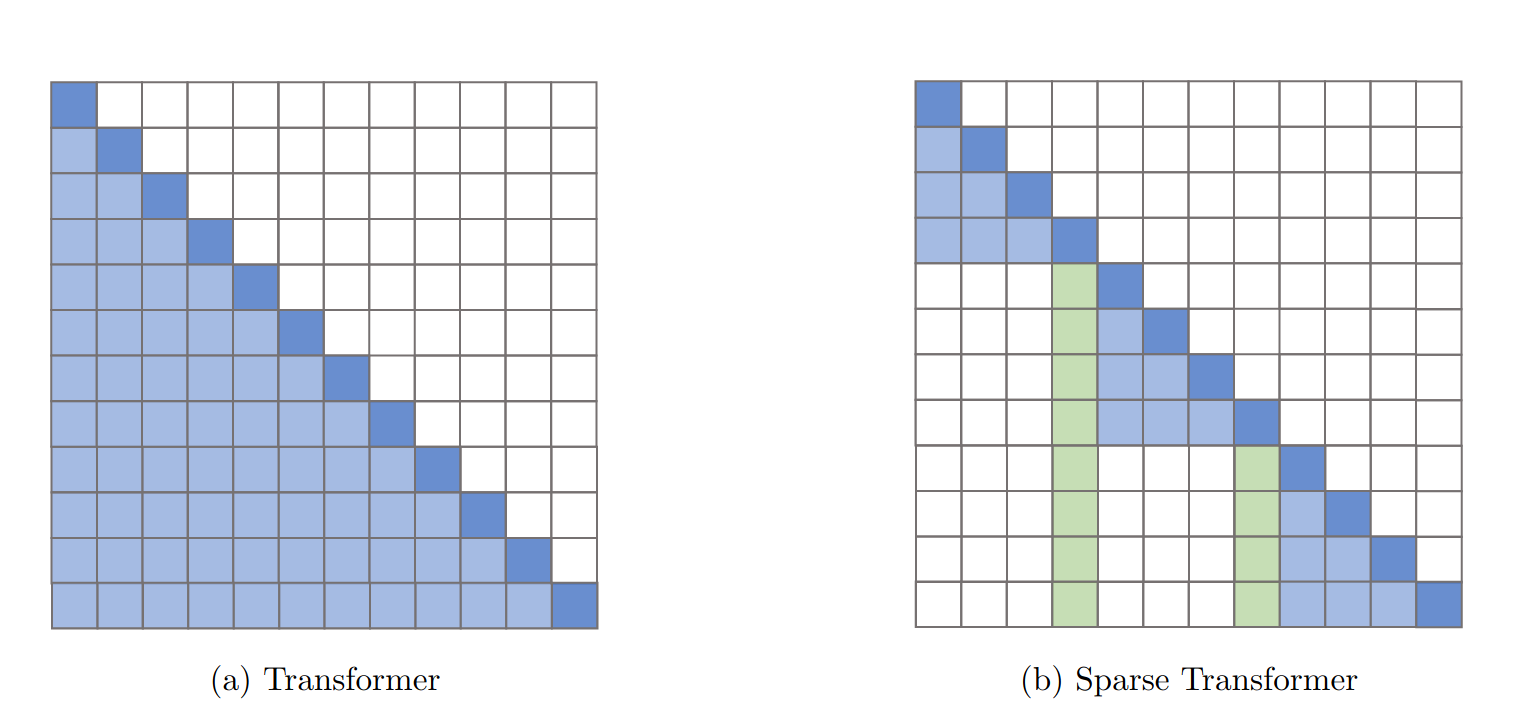
Elementary reductions block or chunk the input sequences effectively quantizing the attention map. Similarly, strided or dilated attention helps to sample the input sequence. New schemes can be devised by combining these simple fixed patterns.
Advancing from handcrafted patterns, researchers considered learned attention maps. Some work reduces the token embedding space bucketing with LSH or using KMeans clustering.
Alex Graves suggests we consider “memory as attention through time” guiding research to introduce side-memory to limit the scope of a model’s attention.
Another conventient reduction is to assume a low-rank structure of the attention matrix to pass to a smaller N x k approximation (k « N). Ideas like kernel approximations and projection through Orthogonal Random Features offer this approach.
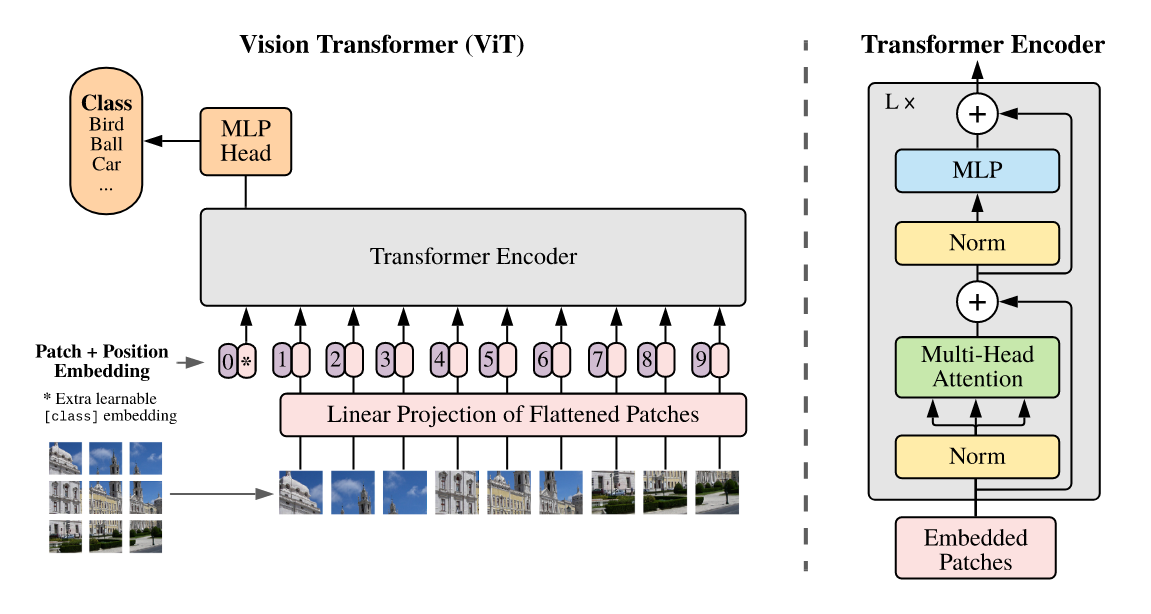
Vision Transformers (ViT) highlighted the potential for transformers in computer vision achieving SOTA performance comparable to models like Noisy Student and Big Transfer (BiT) across vision tasks after pretraining on larger (10M-100M) datasets.
The researchers reduced the compute bottleneck by tokenizing an image into patches while pointing out that specialized attention patterns suffer from a practical lack of hardware-accelerated implementations.
Transformers were further enhanced using Self-Supervised Learning (SSL) in Microsoft’s EsViT. Researchers borrow from BERT’s masked language modeling to incorporate local correlation information. This entails adding a term to the loss which encourages a student model to match a teacher’s soft label for a query patch, provided access only to distorted neighboring patches.
Facebook research into data-efficient Vision Transformers DeiT shows performant models trained on ImageNet-scale datasets. Researchers were interested in learning Transformer-based student models which benefit from the inductive bias of ConvNet-based teachers through knowledge distillation.
ConViT is another example hybridizing Transformers and ConvNets to endow the model with its inductive bias by initializing gated positional self-attention with convolutional priors using spatially-localized attention maps while relaxing any hard locality constraint.
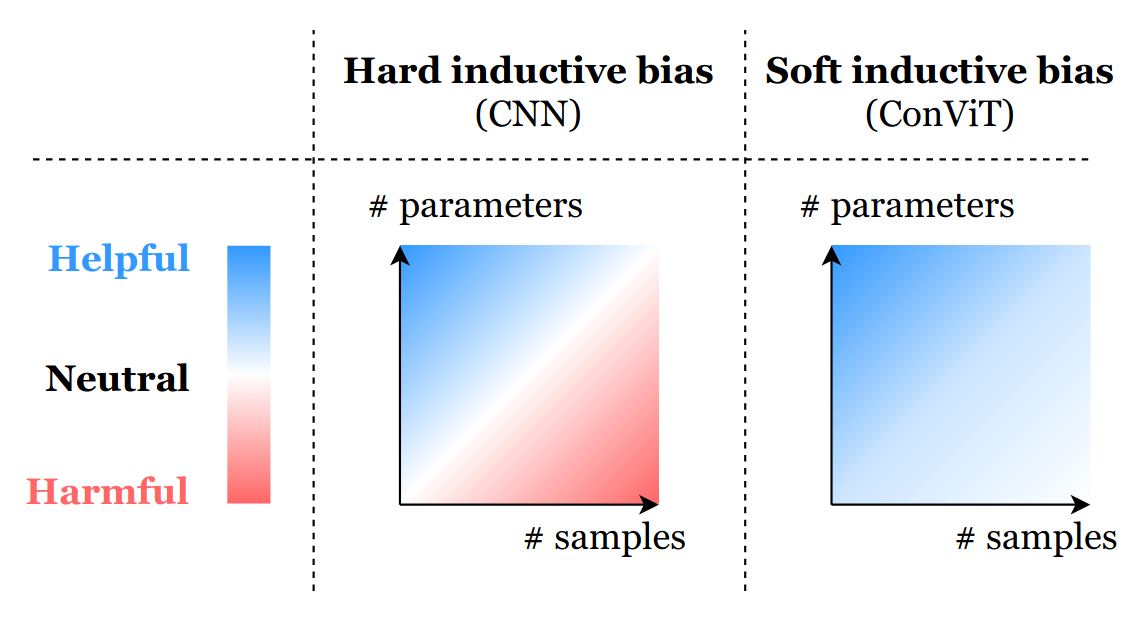
The hard locality constraint enforced using convolutional layers helps mitigate the curse of dimensionality, but in the large data limit, may inhibit a model’s capacity to identify interactions occurring over larger spatial scales.
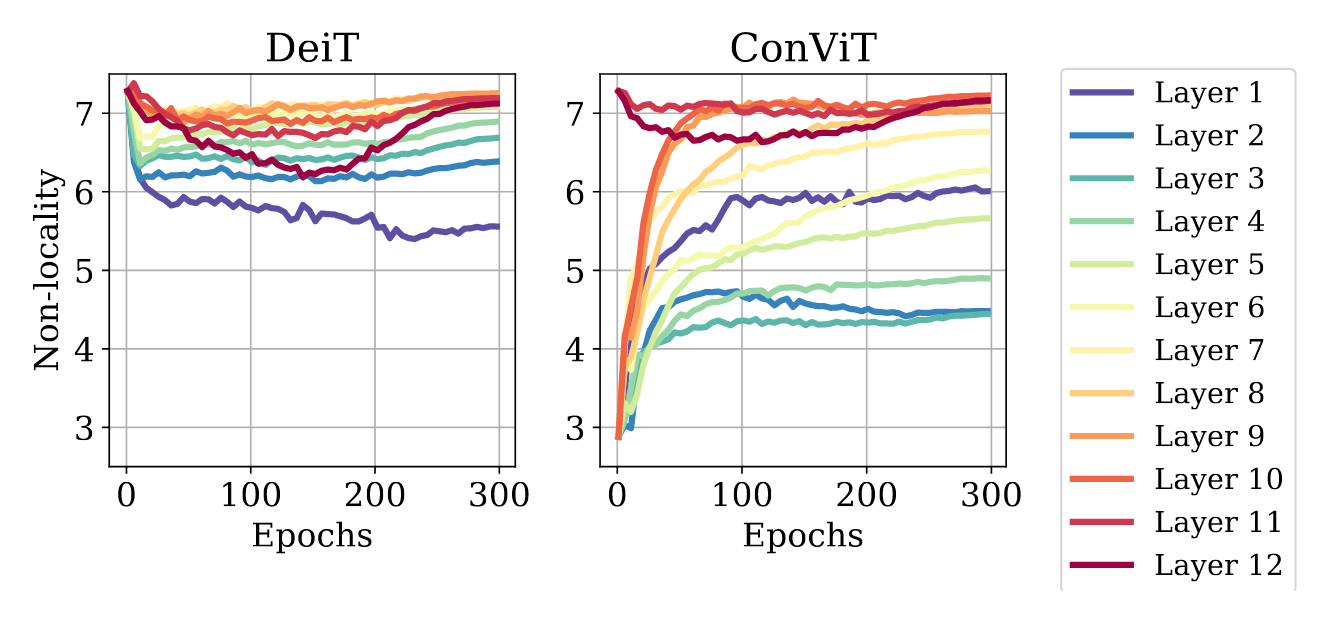
Comparing DeiT and ConViT with an aggregate metric of the attention-weighted distance between query and key patches, researchers find higher layers of ConViT attend to long-range interactions while promoting more diverse attention maps.
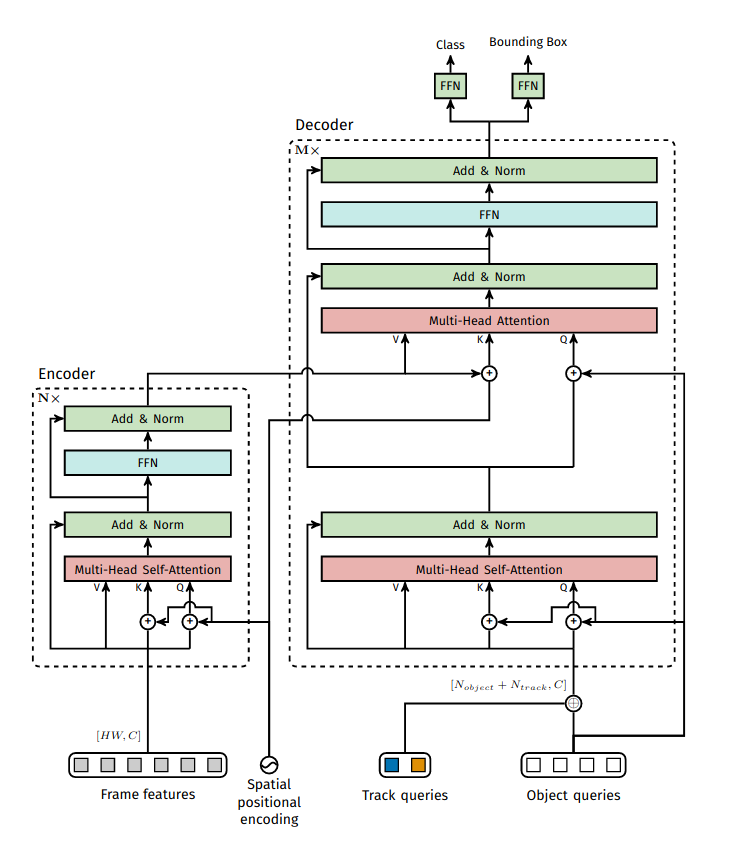
Considering the effect of initializing spatially-localized attention maps for training, we might ask whether attention maps concentrated in space-time could be useful in video object tracking. TrackFormer achieves tracking-by-attention after encoding frame level features extracted with a CNN backbone while dispensing with graph-based matching routines or appearance and motion models.
DeepMind’s Aloe applies self-supervised learning perform object tracking with transformers while characterizing the need to determine an appropriate level of resolution for input.
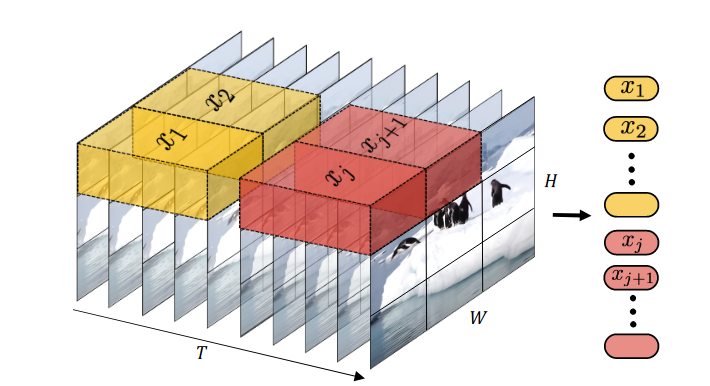
The Video Vision Transformer (ViViT) introduced a logical extension of spatial patches into the time dimension with tubelets:
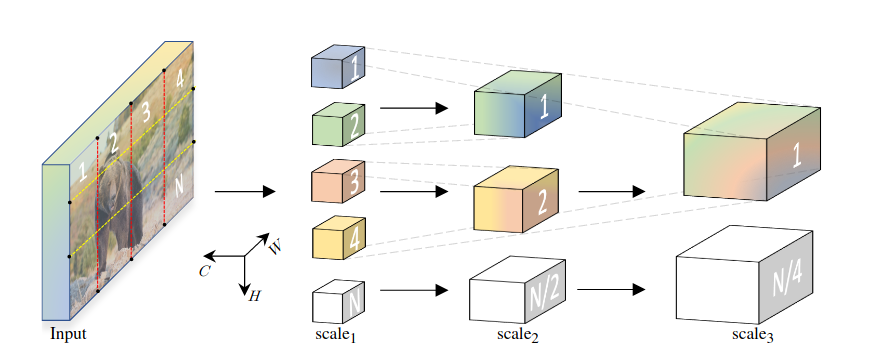
Multiscale Vision Transformers introduced a hierarchical pooling attention which researchers contend helps the model to break permutation invariance and make better use of temporal information.
Even as Transformer research trends toward stronger data-driven priors, FNet shows the power of structured mixing. Researchers note a nominal reduction in accuracy on the GLUE benchmark by simply swapping the $$O(N^2)$$ self-attention in a BERT architecture for the highly-optimized $$O(N *log(N))$$ FFT. Perhaps this work has an extension to the image domain by applying FFT over image patches.
FNet authors suggest applications as a student model in knowledge distillation for deployment on resource-constrained environments.
Stanford researchers were motivated to introduce similar reductions to reduce computational bottlenecks of 1x1 depth-wise separable convolutions in MobileNet.

Others explored tiny Transformers for edge devices like the Arduino Nano BLE Sense, though limited by available tflite-micro ops. Making an addFNetMixer custom op for convolution by FFT could be an exciting contribution!
DeepMind researchers recently test the limits of Transformers over various data modalities including: audio, video, point cloud and text with Perceiver. This model utilizes cross-attention modules and latent factor projection to scale to high-dimensional input.
This success frames Transformers as the general purpose architecture and castes the utility of specialized architectures in doubt given the prevalence of big data. Indeed, researchers find Transformers generalizing well even to weakly-related tasks as training dataset scale increases.
After surveying the fontiers of research, we might conclude that specialized architectures like convolutional layers will remain en vogue for CV practitioners working in the small-medium data regime. But given sufficient volume of training data and/or aggressive augmentation and transfer learning, Transformers may reach higher performance using patterns learned over greater spatial scale.
We are learning to apply Transformers more generally and efficiently and expect to track increased adoption in ML systems.
Our first vision experiment using Transformers trains deit_base_patch16_224 over 100K theatrical posters labeled with one of 22 primary genre labels. After a few ours of fine-tuning with 2 Titan RTXs, our classifier reaches 80% accuracy on the approximately balanced dataset.
Consider these sample images and corresponding model logits for qualitative review.
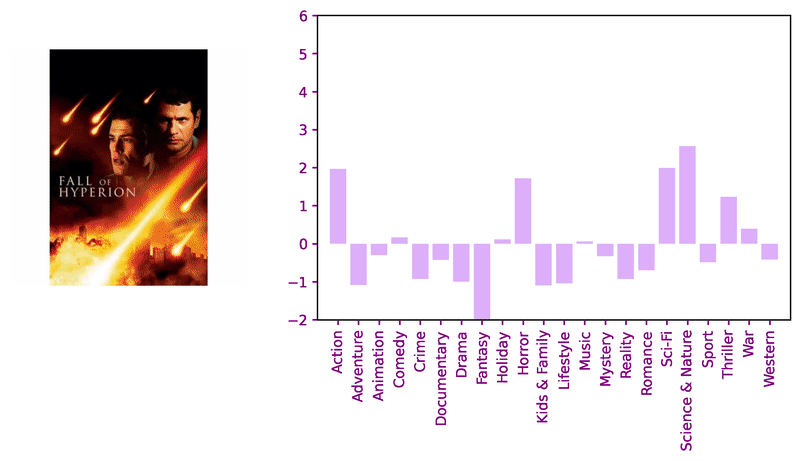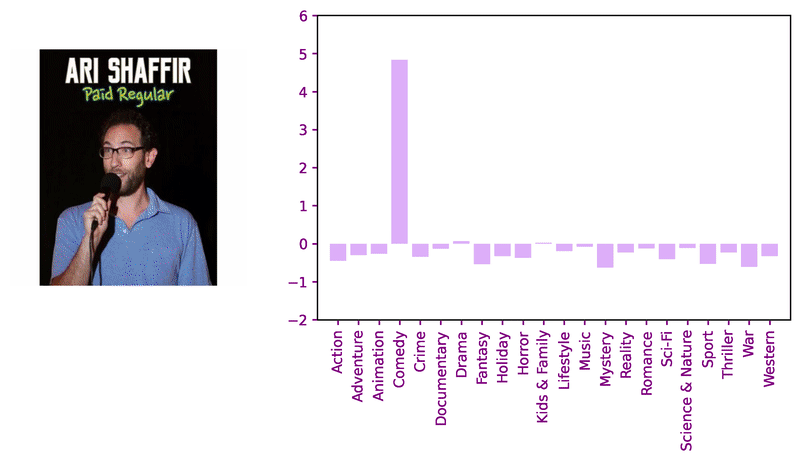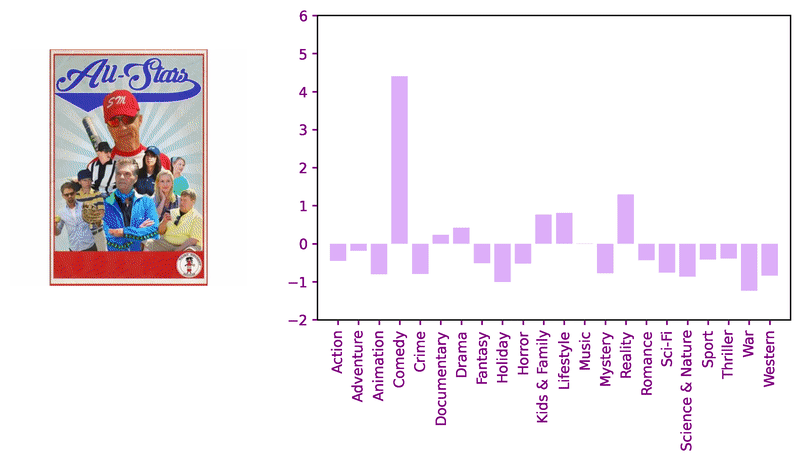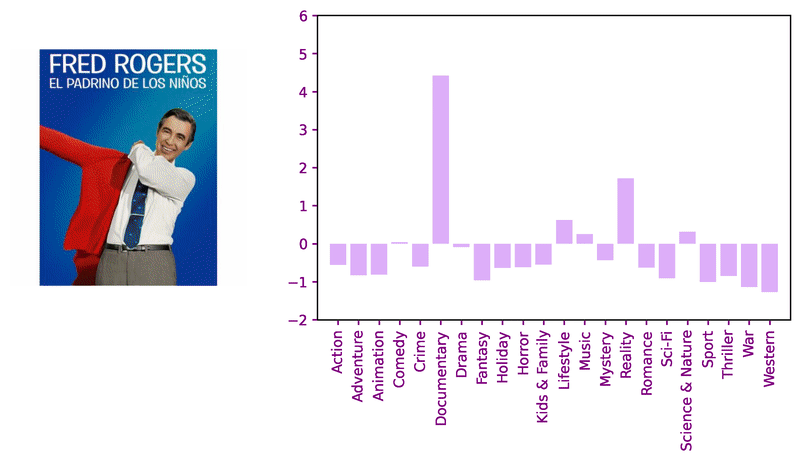
Encouraged by the classifier’s performance, we decided to apply transformers for image similarity to compare against previous work. Adapting the DeiT approach with a keras implemention, we pair a ViT-based student with a ResNet-based teacher using knowledge distillation to fine-tune a genre-classifier before fine-tuning with the triplet loss.
While the ResNet50 teacher takes 224x224 input, we consider much lower resolutions for the ViT student:

We conjecture this extreme reduction can be justified in observing that theatrical posters are quite structured by conventional motifs designed to signal theme & genre. Further, we anticipate simple patterns like color palette and featured objects convey most of the signal, whereas edges and text or otherwise high-frequency information may offer lower-order improvements, hindered somewhat by sparse representation.
This extensive ViT comparison indicates that transfer learning can be quite effective for training ViT models and augmentation helps to match performance of models pretrained on much larger datasets. They also find larger patch sizes perform better than smaller model architectures.
A recent paper offers tips for successful knowledge distillation which guided our augmentation strategy. Starting with a genre classifier trained from scratch with logloss, we fine-tune with triplet-loss.
As recommended in the ViT comparison above, we can use transfer learning, selecting similarity model architectures by evaluating validation accuracy in the upstream classification task, which is much faster to train!
With an average of two genres labels per title, our dataset lends to multiple representations and augmentation strategies. For instance, we might consider each genre label to provide a new training sample. On the other hand, by framing a multi-label classification, we aim to utilize covariance in genre label distribution to enhance our distillation.
In another experiment, we apply the Multiscale Vision Transformer (MViT) to videos cropped down to faces for deepfake detection. With small changes to the config MVIT_B_16x4_CONV.yaml, we reach 75% validation accuracy on the balanced binary classification task, training the model on roughly 7K samples from scratch.
We also tried training this model on more of the raw deepfake detection challenge videos. However, focusing the model on faces with a detection pipeline proved to powerful an inductive bias to pass up for this small sample.