While prototyping YogAI, our smart mirror fitness application, we dreamed of using generative models like GANs to render realistic avatars.
For the TFWorld 2.0 Challenge, we came a bit closer to that vision by demonstrating a pipeline which quickly creates motion transfer videos.
More recently, we have been learning about reconstruction techniques and have been excited about the work around Neural Radiance Fields (Nerf).
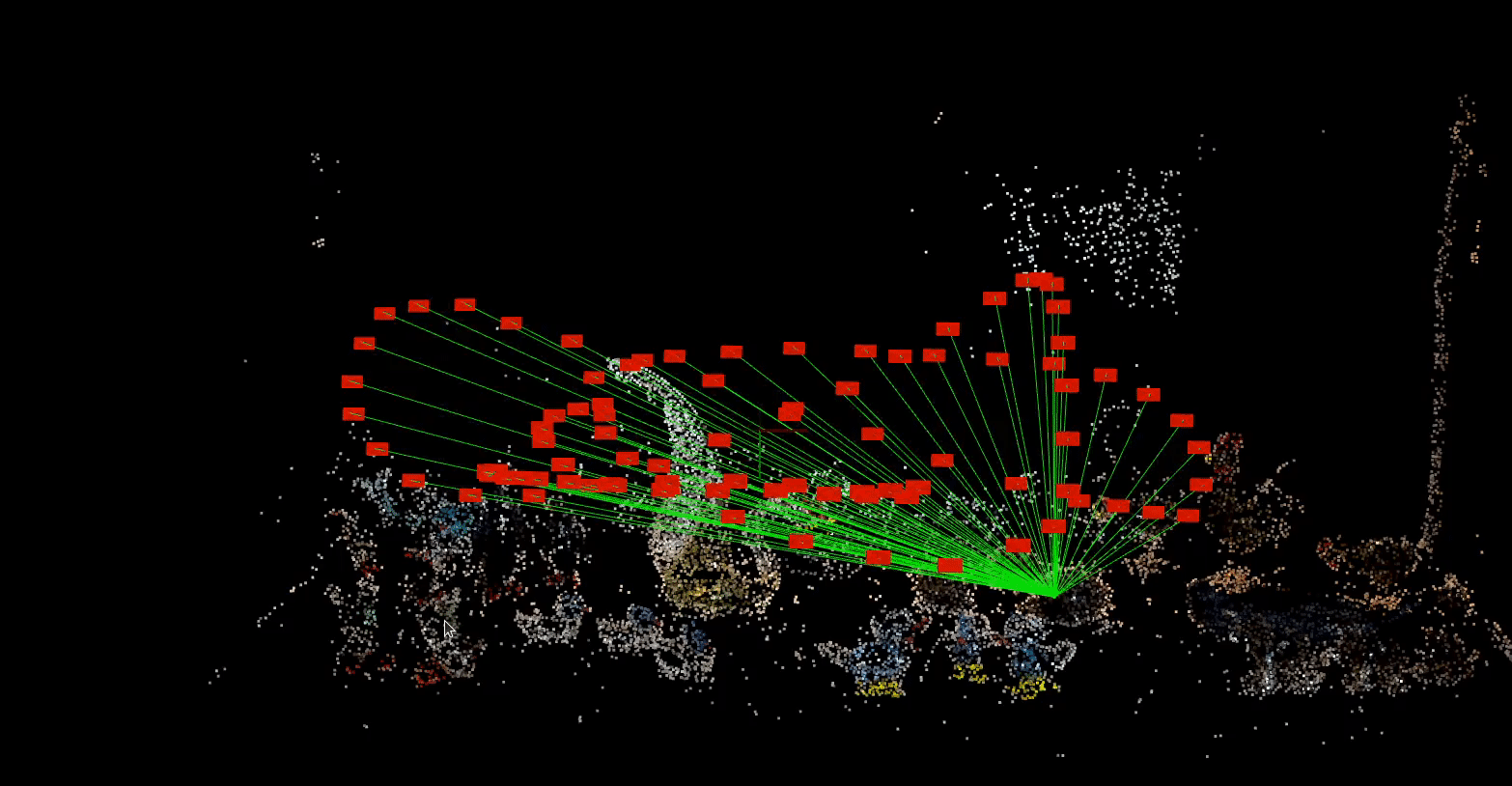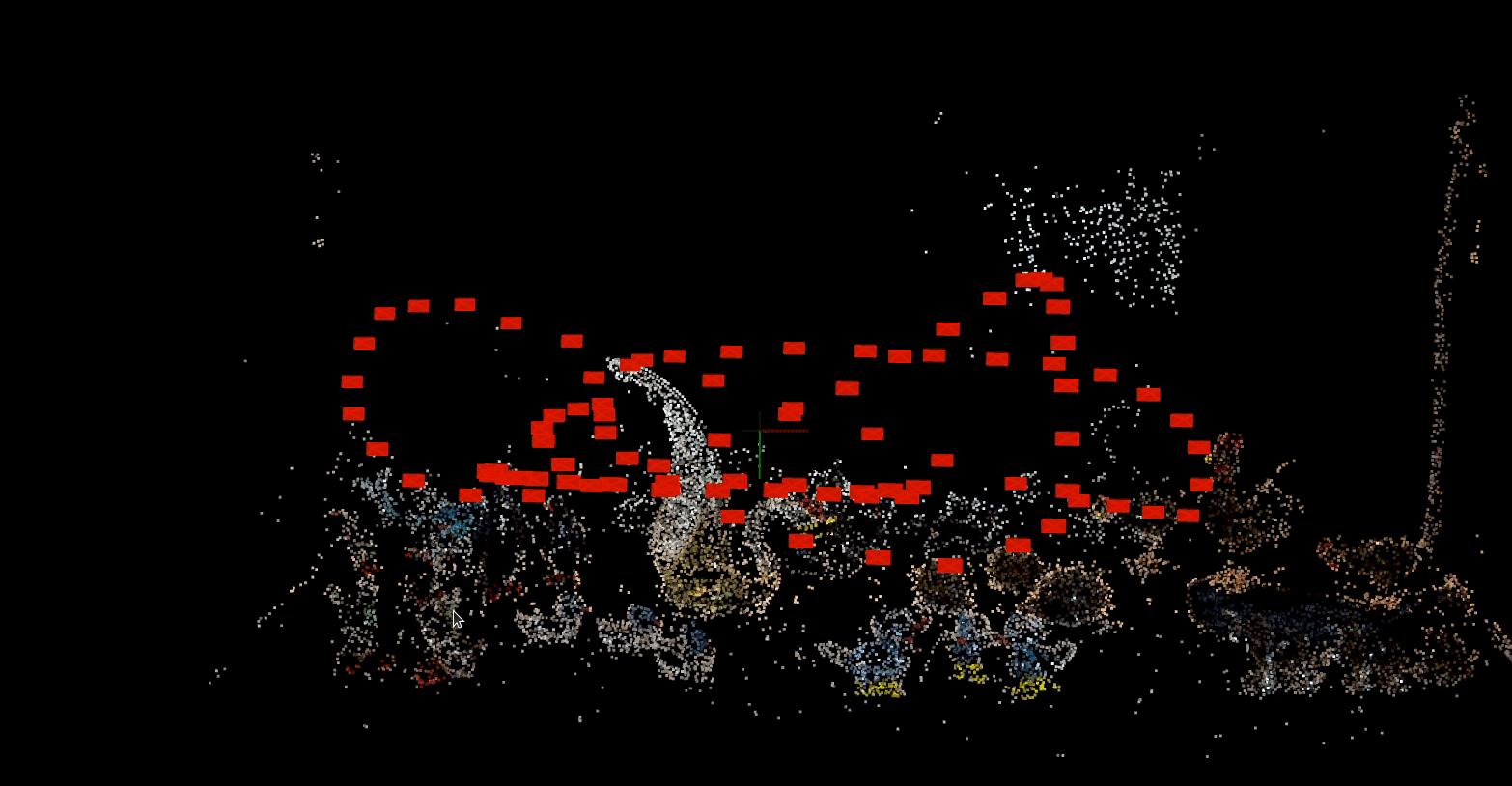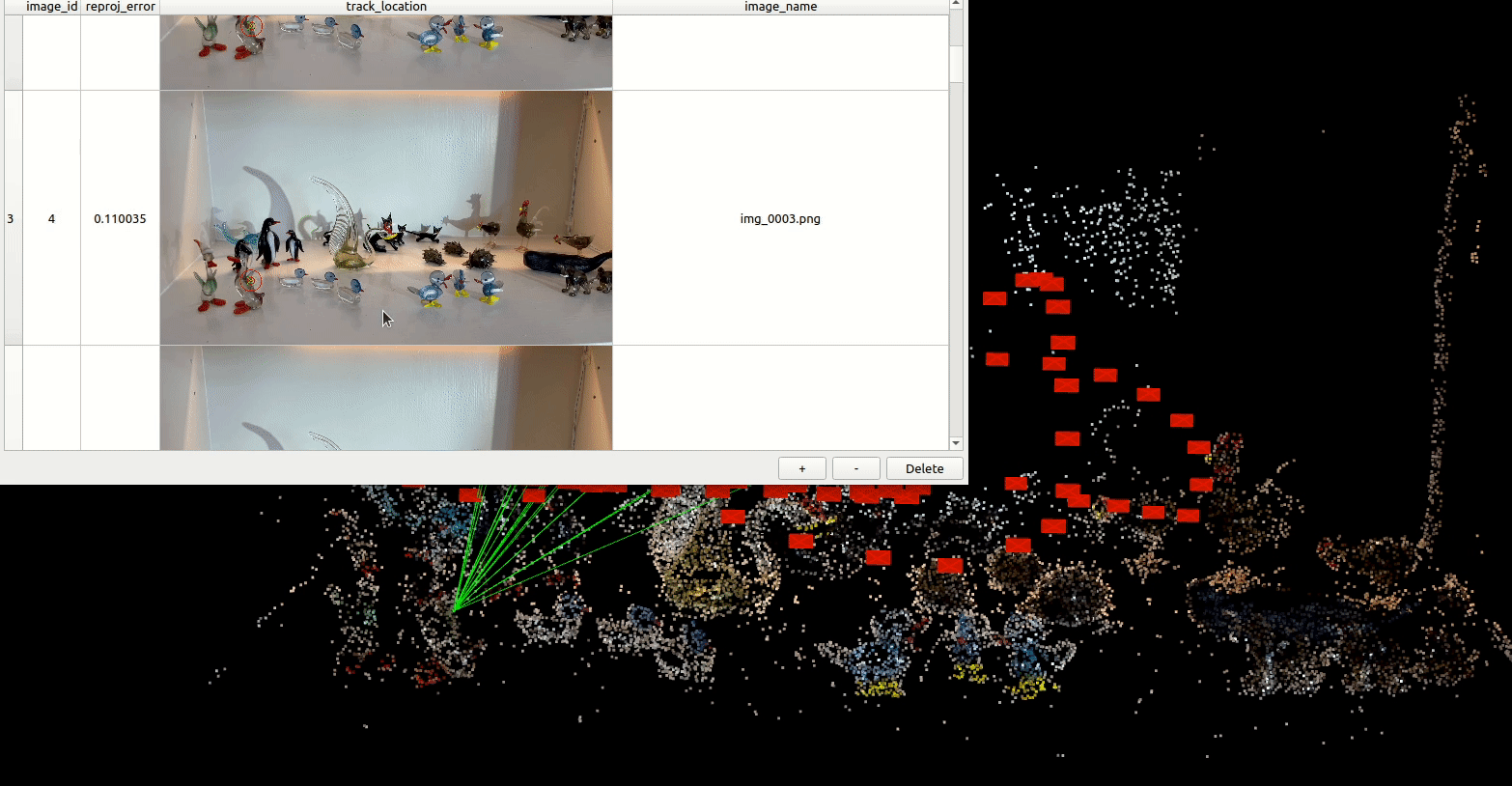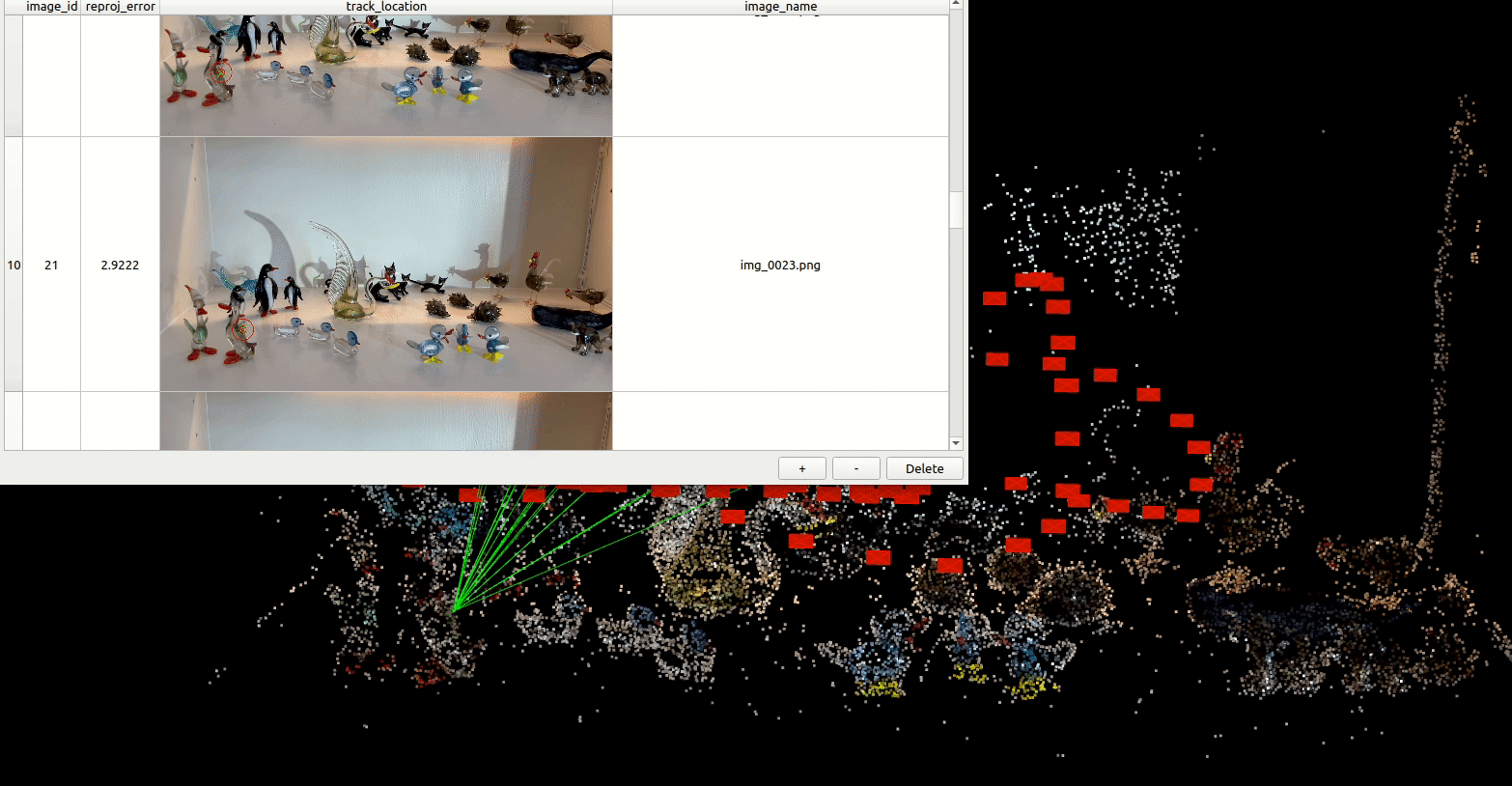
By this method, one learns an implicit representation of a scene from posed monocular videos. Typically, you start with video and use tools like colmap in order to align frames with camera poses.
The red markers indicate camera poses for each frame of a short video recording of glass figurines on a shelf.
With a trained nerf model, you can render novel views of the scene for a given input camera pose!

This last sequence was generated after training DSNerf, which supervises training with depth information we get for free by running colmap to process our input video. Adding depth-supervision to the loss aids model convergence while training on fewer samples.
Using simple scenes and limited perspectives, nerf can generate very realistic renditions. Next, we try a highly varied perspective of a complex, highly occluded scene of a figtree.

Less surprisingly, the rendition is not nearly as realistic as in the previous input scene.

Our latest experiment uses ml-neuman, decomposing a scene before applying nerf to represent a person.
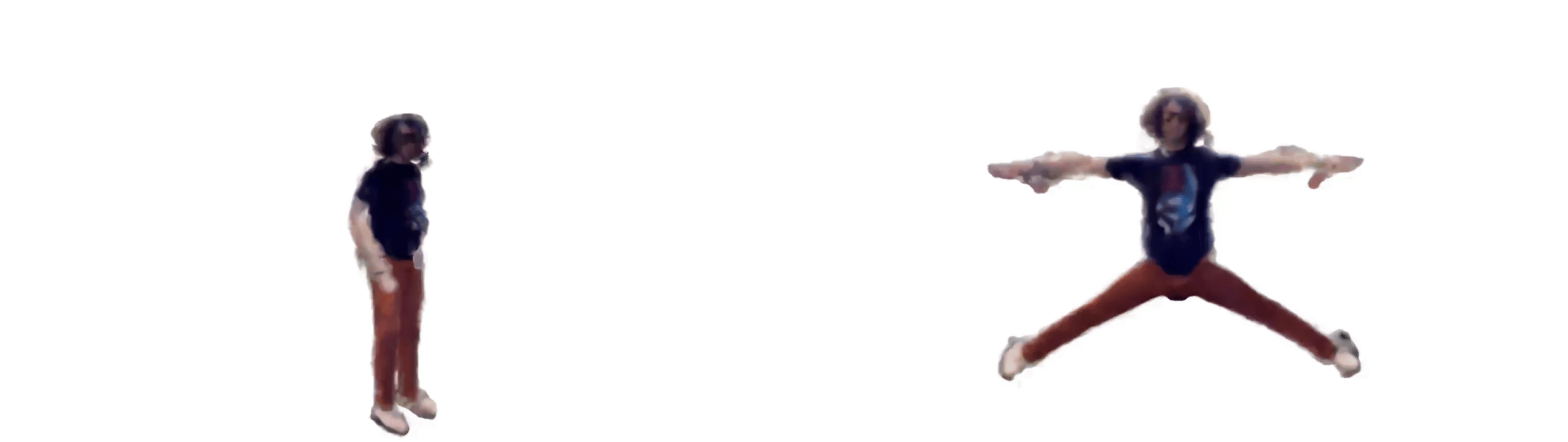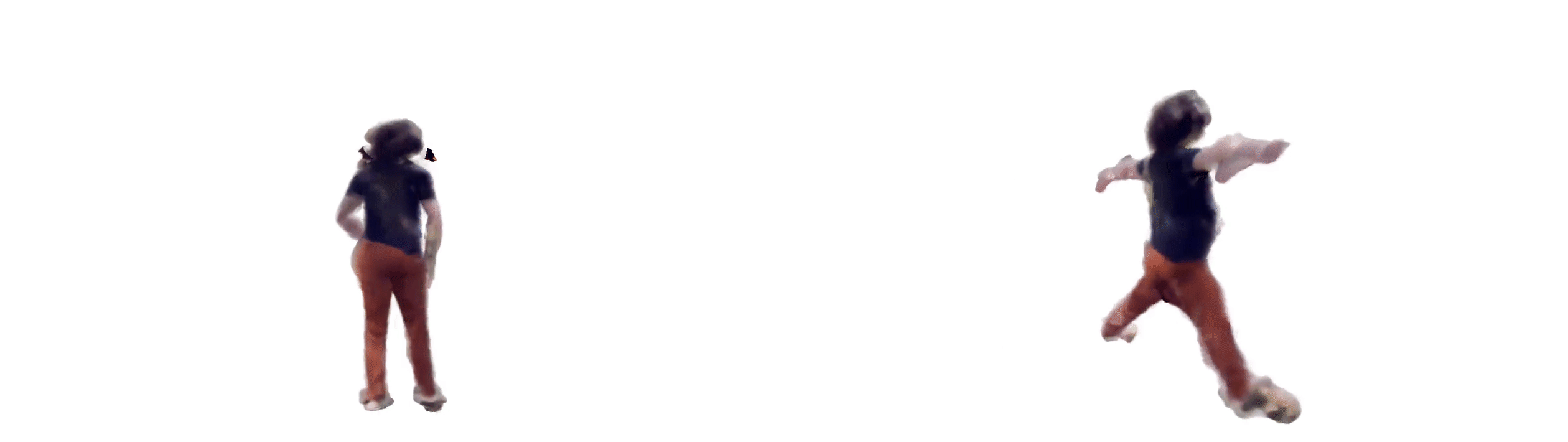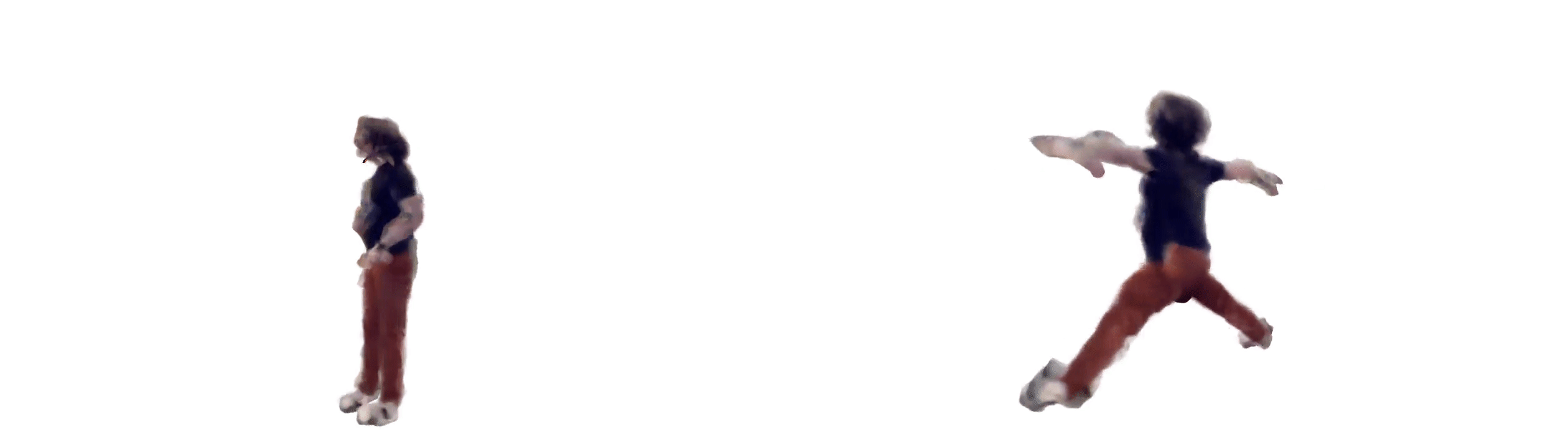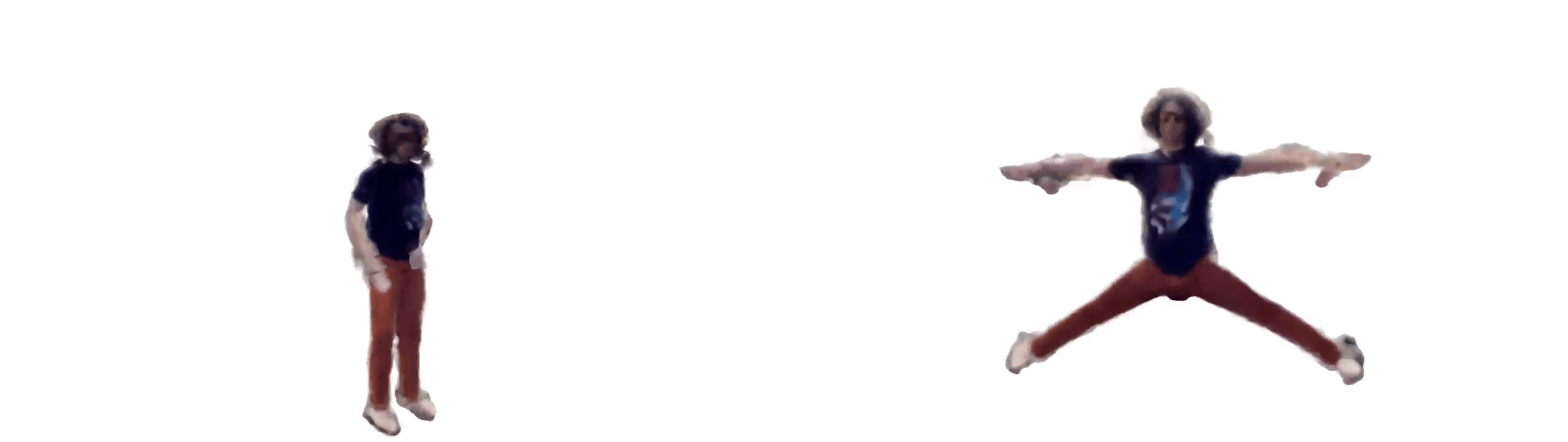
For a successful rendition, we found it best to:
- record in landscape mode and NOT portrait to avoid distortions
- maintain a steady tracking shot with person in full FOV
- train on a GPU with 24GB RAM
- vary body position/orientation
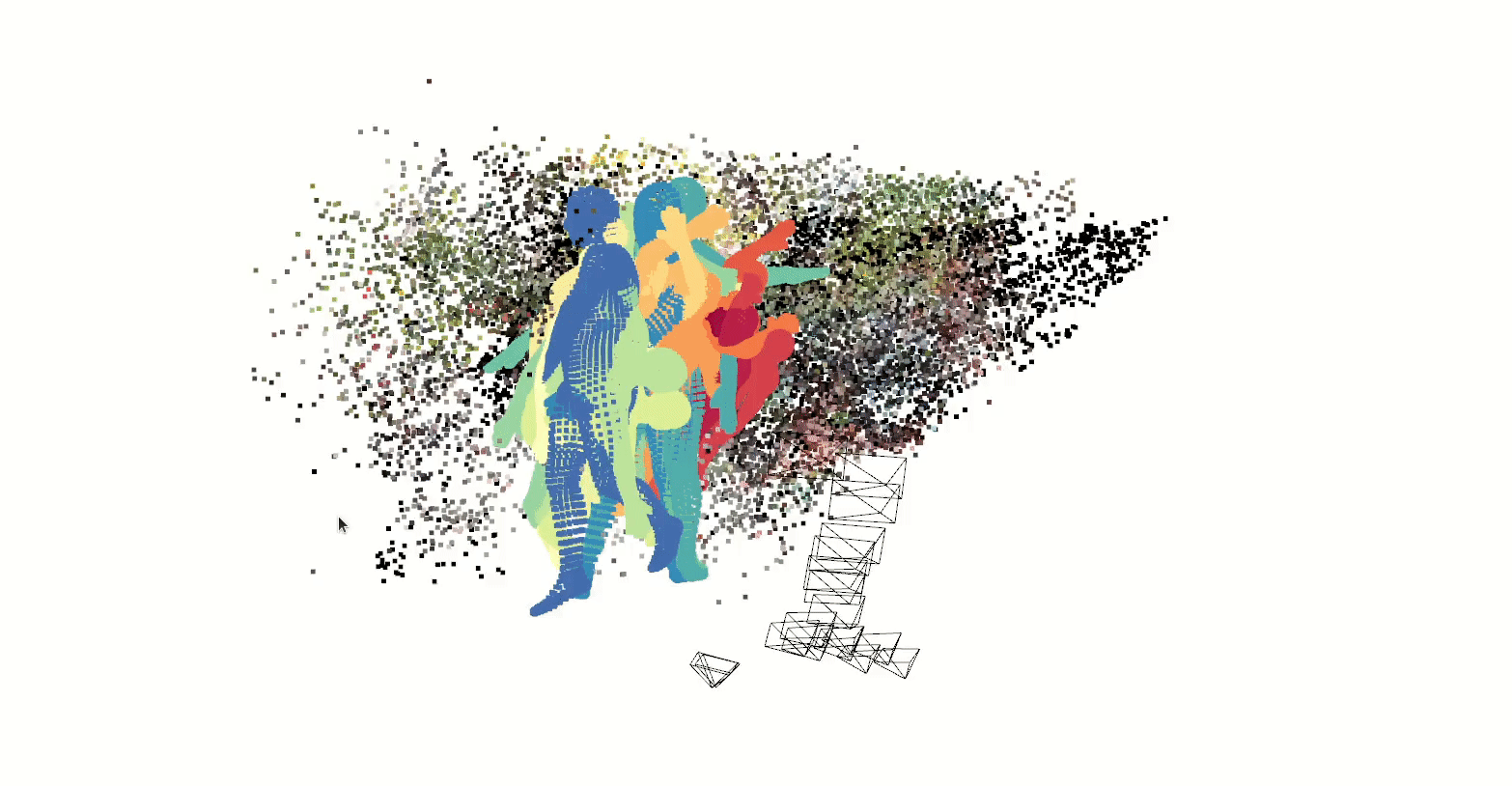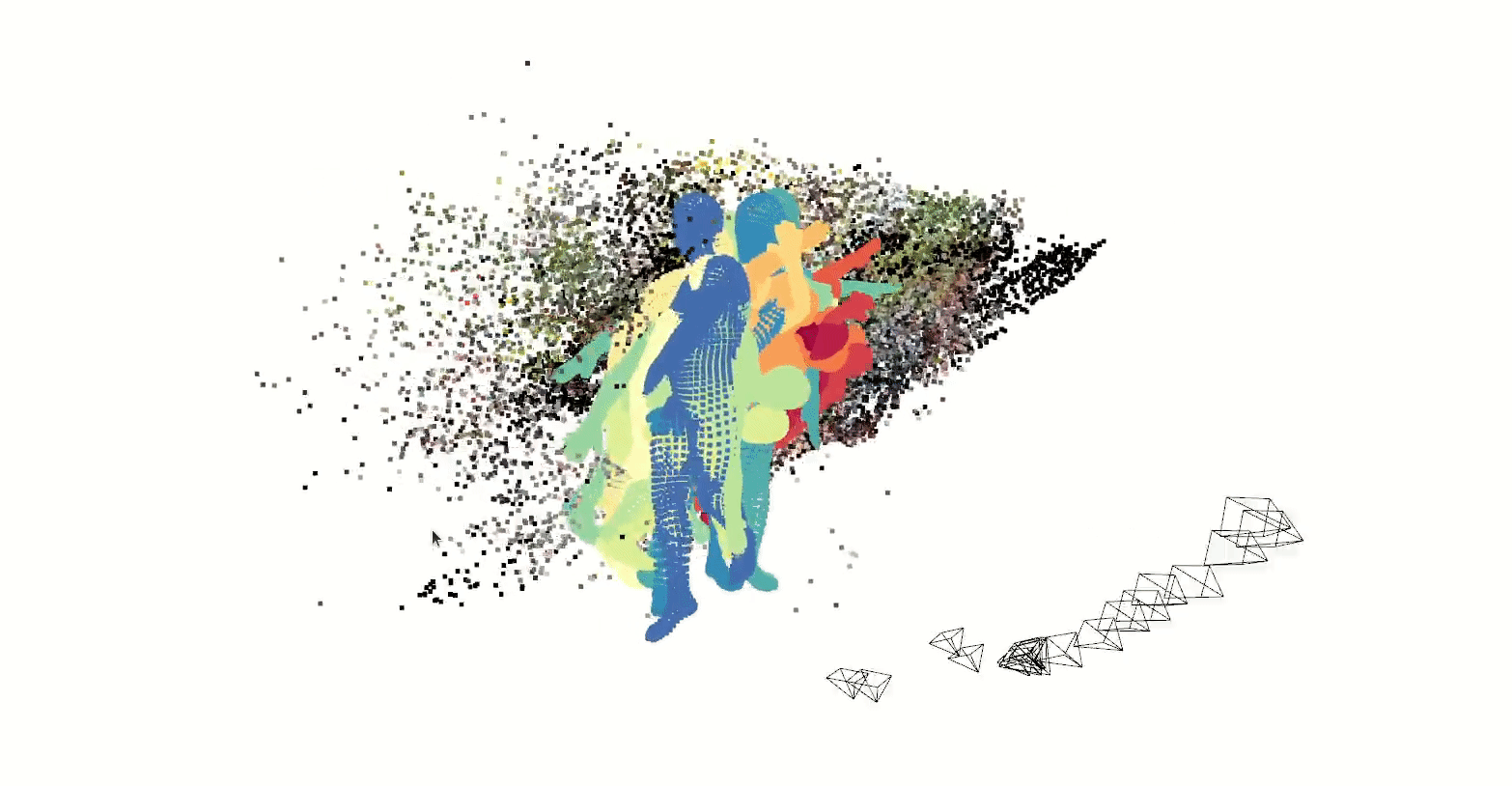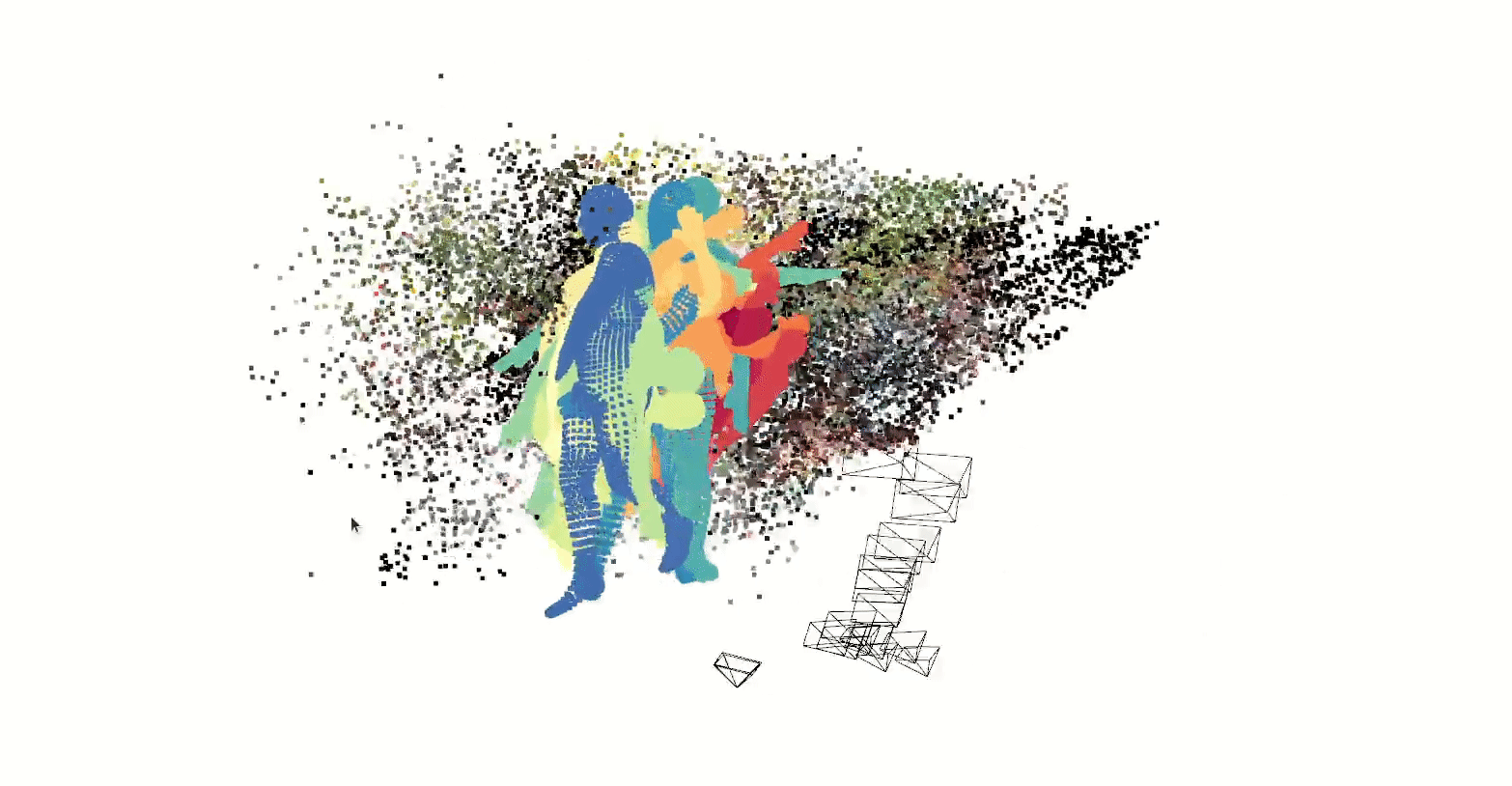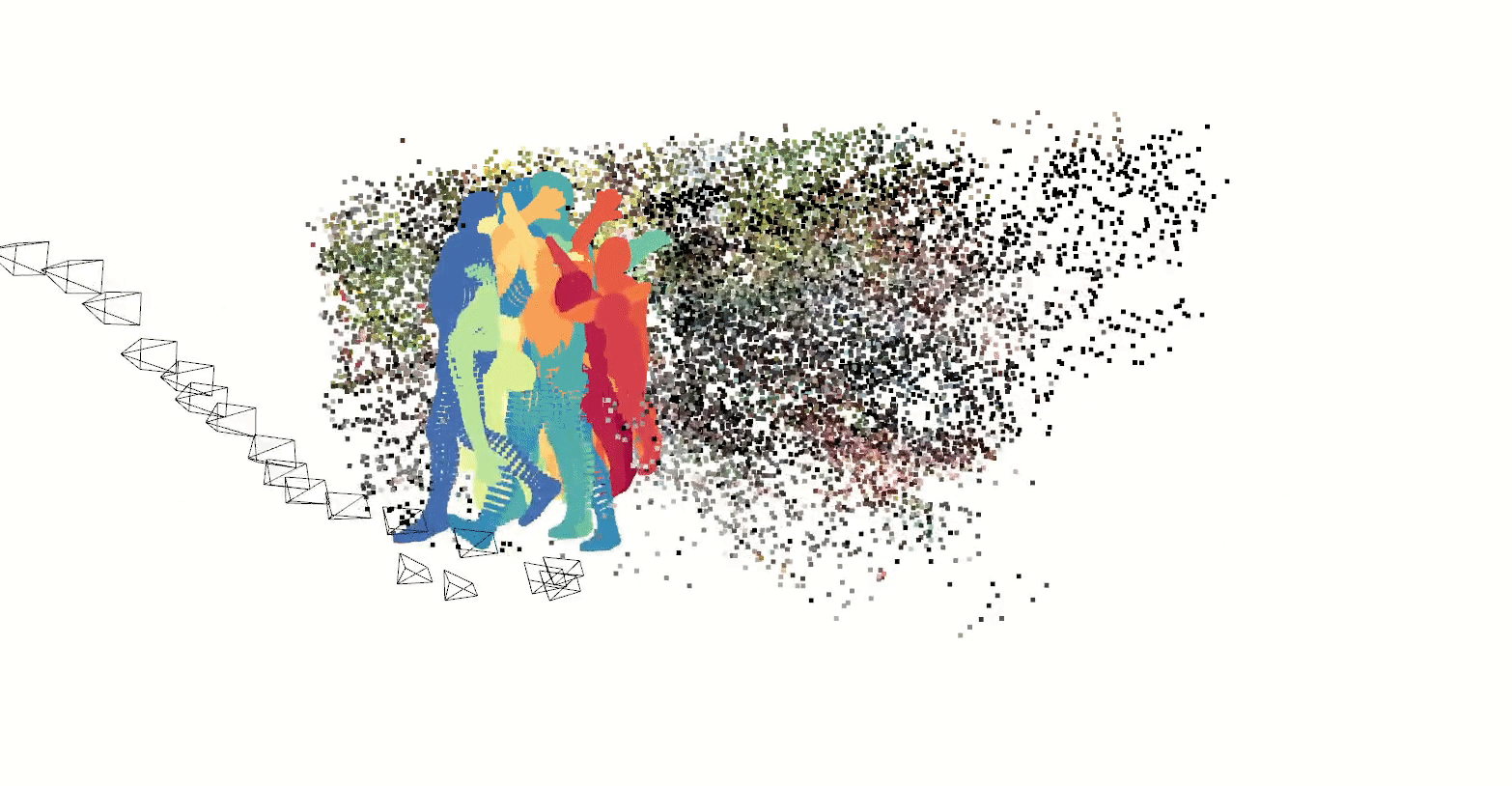
Nerfs can render from many perspectives given relatively few training samples, which could have applications for sim2real in model training with synthetic data.
Some works focus on improvements using other supervisory signals or on making inference faster and we are excited to explore these developments as the technology matures.
