Scrapy is a powerful web scraping framework and essential tool for building machine learning datasets.
For sites with simple structure, scrapy makes it easy to curate a dataset after launching a spider. Check out the tutorials in scrapy’s documentation.
To train a poster similarity model, we first gathered hundreds of thousands of movie posters.
More concretely, when scraping IMDb.com, we may be interested in gathering posters from <img> tags under <div> tags with the class "poster".

However, this overlooks many additional images.
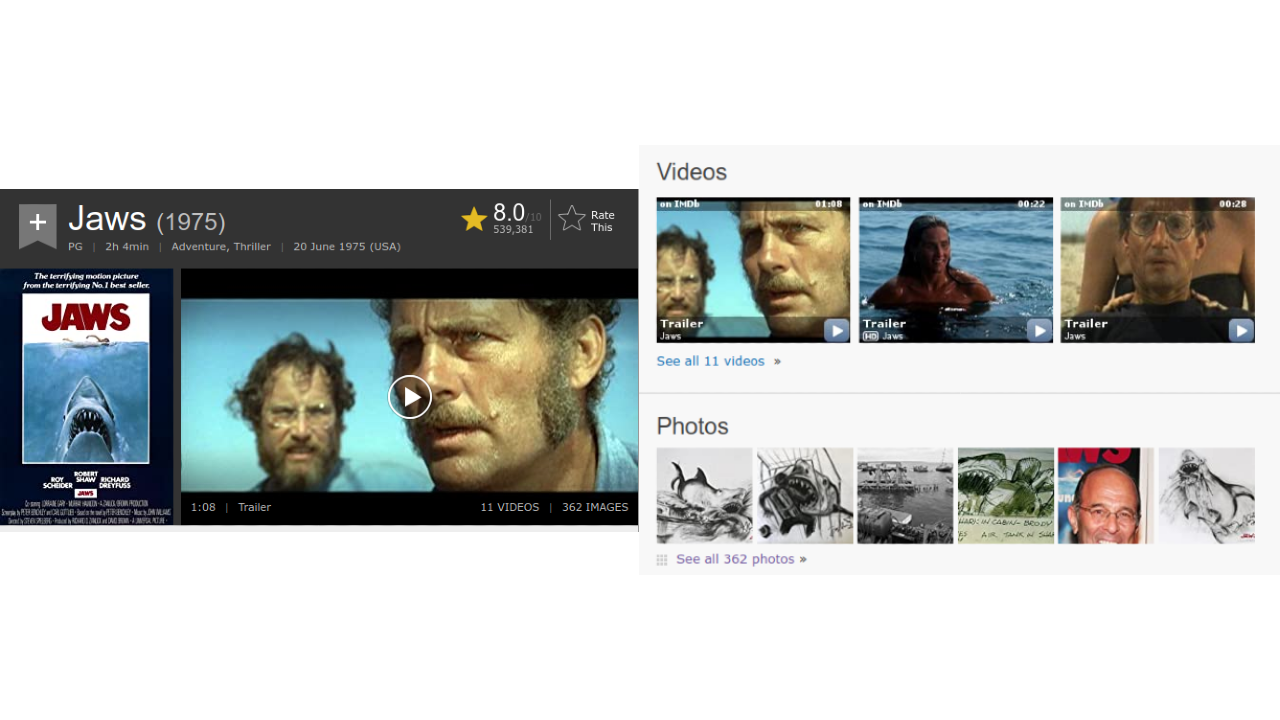
Still other sites like wikipedia host posters in the Infobox film template, which can be extracted by parsing the wikipedia dump.
Though we can precisely pull target images after designing specialized xpath selector logic, we prefer a more robust scraper. Ideally, we can gather all assets associated with an image tag without downloading a bunch of irrelevant images like favicons, logos, or redirects to a valid off-domain link.
Our smart scraper begins with Images Pipelines. This pipeline offers a lot of functionality to persist images to the cloud, to disk, or serving over FTP, avoiding repeating recent downloads, and more.
We would like to run inference with trained image detector/classifier models to determine whether an image is downloaded based on content.
This helps us to achieve greater recall in downloading relevant images without overly brittle scraper logic.
Inspecting the image pipeline source code, we find line 124 is a good place to introduce an inference step from an image classifier to help filter irrelevant images.
The ImagesPipeline class implements logic in the get_images() method to filter out images that do not meet the minimum width and height requirements. Similarly, we introduce logic to filter out images not matching a target image label.
def check_image(self, image):
"""
Returns boolean whether to download image or not
based on labels of interest.
Input args:
image = PIL image
"""
img = image.resize((224,224), Image.NEAREST)
img = np.expand_dims(np.array(img), axis=0)
preds = self.model.predict(img)
top_3_preds = preds[0].argsort()[-3:][::-1]
if any(label in top_3_preds for label in self.labels):
return True
else:
return False
Let’s Go Fishing!
In this toy example, we’ll switch to filtering images, favicons, logos from Wikipedia for a label found in the ImageNet dataset so we can simply refer to pretrained models on Tensorflow Hub.
# Added to the ImagesPipeline class initialization:
# Fast mobilenet_v2 model from TFHub using imagenet
self.model = tf.keras.Sequential([
tf.keras.layers.Lambda(lambda x: tf.keras.applications.mobilenet.preprocess_input(x)),
hub.KerasLayer("https://tfhub.dev/google/imagenet/mobilenet_v2_130_224/classification/4")
])
self.model.build([None, 224, 224, 3])
self.labels = [2] # test label for goldfish
As shown above, we’ll try to find goldfish images (label = 2) a site like wikipedia.
This in conjunction with our helper function described earlier lets us only download goldfish images inside <img> tags from the page and ignore irrelevant content.
With a broad crawl and a high-recall image pipeline, our image classifier helps to maintain the quality of the resulting dataset via content-based filtering.
For long-running crawls, we can set labels using crawler attributes and use the telnet feature to update the targeted image category.
You can even analyze screenshots of a target site applying techniques like OCR to understand the content of difficult-to-parse sites.
Similarly, we can use text classification models to analyze text in the response to validate data logged and refine the crawler.
For example, we can run inference in the process_spider_output method of our scrapy project’s middleware to filter items based on the image tag’s alt-text before the downloader even gets the image.
What better way to quickly build up your training datasets than to search more broadly, using inference time to delay requests!