Check out the FilmGeeks3 Collection
In last year’s post on generative models, we showcased theatrical posters synthesized with GANs and diffusion models.
Since that time, Latent Diffusion has gained popularity for faster training while allowing the output to be conditioned on text and images.
This variant performs diffusion in the embedding space after encoding text or image inputs with CLIP. By allowing the generated output to be conditioned on text and/or image inputs, the user has much more influence on the results.
Fine-tuning these models, we created a virtual Halloween costume fitting for our dog, Sweetpea:

Next, we trained a latent diffusion model from scratch on our FilmGeeks movie poster collection:

Stability.ai trained Latent Diffusion on billions of images, using thousands of A100 GPUs before releasing the model as “Stable Diffusion”. This is free despite a total training cost in excess of $600K!
With these pretrained models, you can design a wide variety of prompts to evoke specific themes and aesthetics to generate custom content on-the-fly.
We try using stable diffusion to generate samples conditioned on custom prompts as well as the output of our filmgeeks latent diffusion model.

You can see our favorite samples in FilmGeeks3 on Opensea!
Besides making entertaining images, we experimented with applications like data augmentation. Similar to last year’s synthetic data experiment, we augment sample objects by performing “style transfer” to randomize the image texture before rendering novel perspectives using Blender/Unity.

Stable Diffusion supports transferring themes and concepts learned from a massive corpus of text-image aligned data scraped from the web. For example, we can synthesize a tattooed variant of our image texture above by conditioning on it as input along with a descriptive prompt:
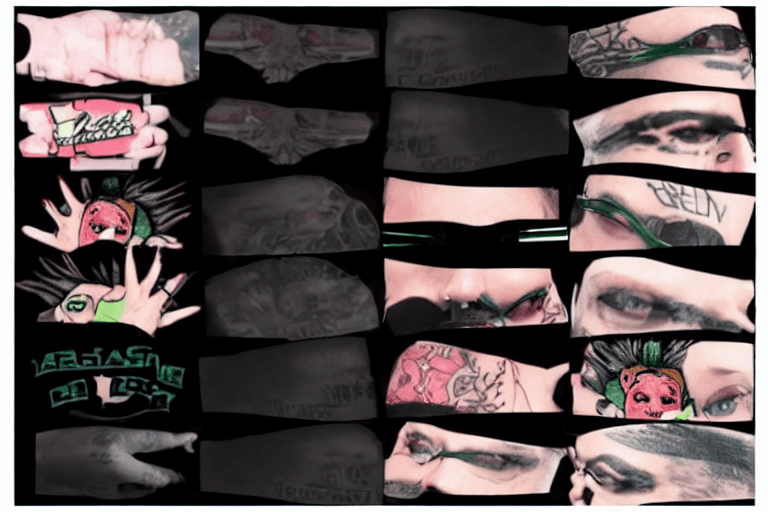
Latent diffusion isn’t only for generating images. Motion Diffusion Models shows how we can synthesize realistic human motions described by the text prompt.

This can be used to articulate SMPL objects through motions that are not well-represented in activity recognition datasets. With 3D rendering, we can generate views from many different perspectives.
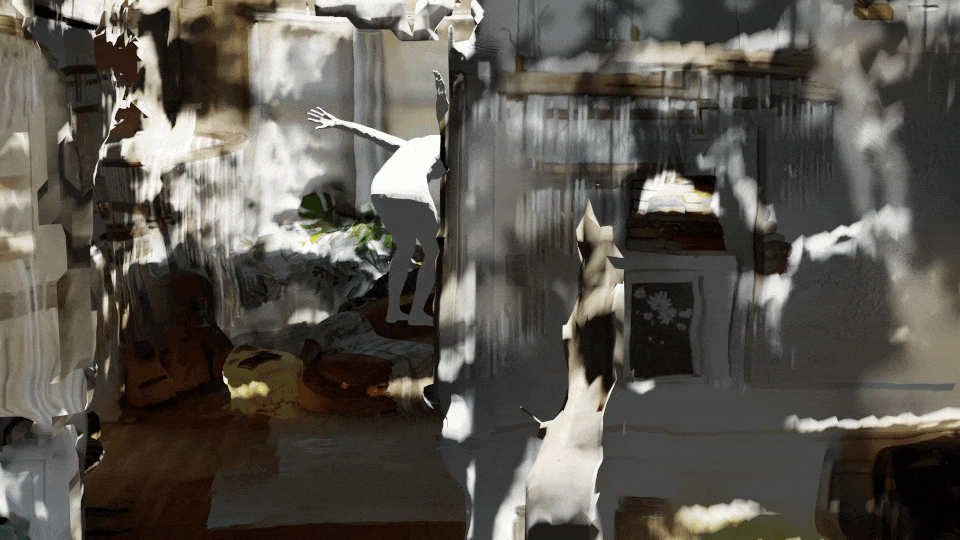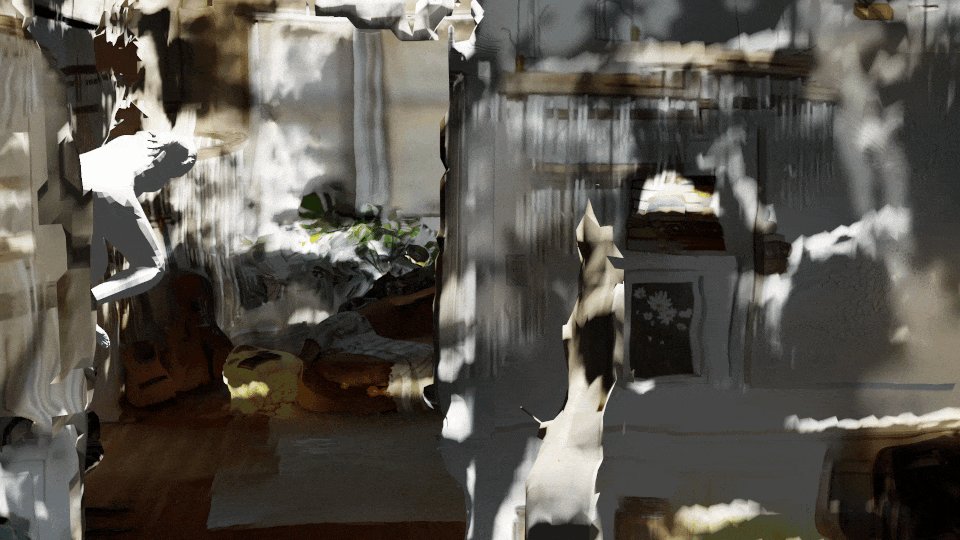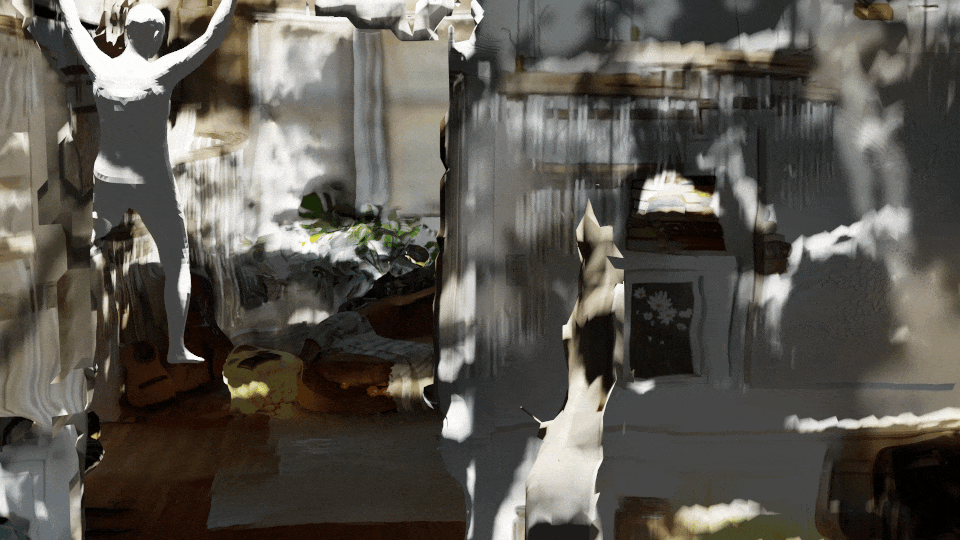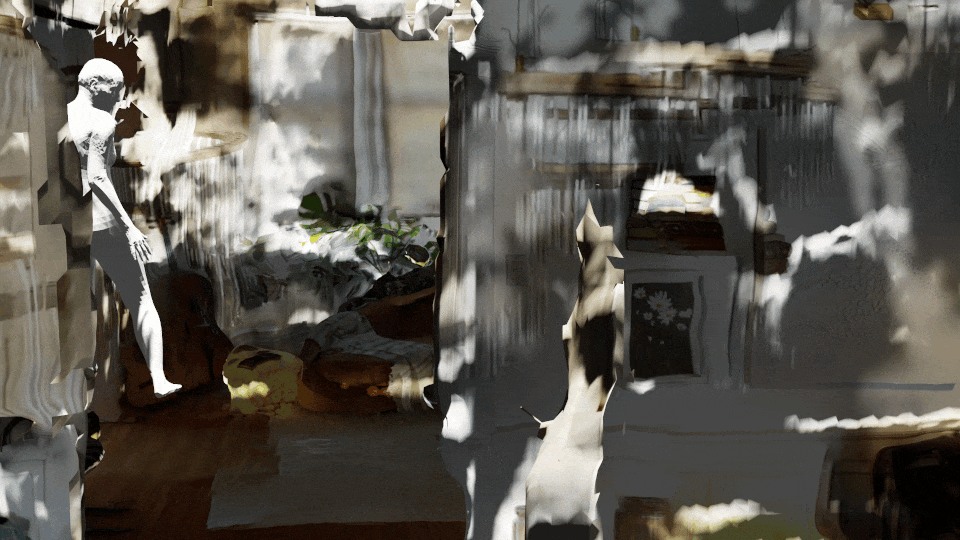
See our video on data augmentation with Latent Diffusion.
Finally, we mention that Latent Diffusion is being used to generate 3D assets as well as video. Using models like Stable Dreamfusion, you can generate 3D assets conditioned on a text prompt like our fish:

Check out some of our other samples on sketchfab:
Powerful, open-sourced models like Stable Diffusion make it easier and cheaper to access high-quality data for human or machine consumption.
Latent Diffusion has the power to condition samples on image and/or text which provides a lot of control in designing datasets specialized for your application.
We are excited to apply these techniques in content generation and few-shot learning from synthetic data.