Intro
In a previous post, we discussed scraping a movie poster image corpus with genre labels from imdb and learning image similarity models using tensorflow.
In this post, we extend this idea to recommend movie trailers based on audio-visual similarity.
Data
We started by scraping IMDB for movie trailers and their genre tags as labels. Using Scrapy, it is easy to build a text file of video links to then download with youtube-dl.
After downloading ~25K samples, we use ffmpeg for fast video processing. The python bindings are convenient for extracting a sample of N-frames and a spectrogram for some audio content.
def _process_video(vid, ss=5):
# generating spectrogram
width= 560
height = 315
crop_width = crop_height = 224
output_spec, _ = (
ffmpeg
.input(vid, ss=ss, t=125)
.filter('showspectrumpic', '224X224', legend=0)
.output('pipe:', format='rawvideo', pix_fmt='rgb24')
.run(capture_stdout=True)
)
spectrogram = (
np
.frombuffer(output_spec, np.uint8)
.reshape([-1, crop_height, crop_width, 3])
)
# generating video segment
output_vid, _ = (
ffmpeg
.input(vid, ss=ss, t=125)
.filter('scale', width, -1)
.filter('crop', crop_height, crop_width, int(width/2 - crop_width/2), int(height/2 - crop_height/2)) #center crop
.output('pipe:', format='rawvideo', pix_fmt='rgb24', r=1/12)
.run(capture_stdout=True)
)
video = (
np
.frombuffer(output_vid, np.uint8)
.reshape([-1, crop_height, crop_width, 3])
)
# pad video if < 10 frames
if video.shape[0] != 10:
shape = np.shape(video)
padded_video = np.zeros((10, crop_height, crop_width, 3))
padded_video[:shape[0],:shape[1]] = video
video = padded_video
return video.astype(np.float32), spectrogram[0].astype(np.float32)
To test different sampling strategies, we initially used this function in the callback of a generator to load data in training.
class ImageGenerator(tf.keras.utils.Sequence) :
"""
Generator for fast dataset construction
"""
def __init__(self, filenames, labels, batch_size) :
self.filenames = filenames
self.labels = labels
self.batch_size = batch_size
def __len__(self) :
return (np.ceil(len(self.filenames) / float(self.batch_size))).astype(np.int)
def __getitem__(self, idx) :
batch_x = self.filenames[idx * self.batch_size : (idx+1) * self.batch_size]
batch_y = self.labels[idx * self.batch_size : (idx+1) * self.batch_size]
samples = {'spectrogram_input':[], 'video_input':[]}
for fl in batch_x:
spec, vid = _process_video(fl)
samples['spectrogram_input'].append(spec)
samples['video_input'].append(vid)
samples['spectrogram_input'] = np.array(samples['spectrogram_input'])
samples['video_input'] = np.array(samples['video_input'])
return samples, batch_y
Movie trailer also exhibit some structure we can use. For example, we may trim the beginning and ending segments to focus on the content. Trailer also show wide variability in aspect ratios so we can simply center crop after a resize. In general, we sampled 10 frames from most trailers by taking one every 12 seconds and padding short trailers.
For efficient loading, we convert the samples into tfrecords.
Model
Similar to our movie poster similarity model, we used genres as labels for our samples. To process both inputs, we designed a two tower model with an architecture like:
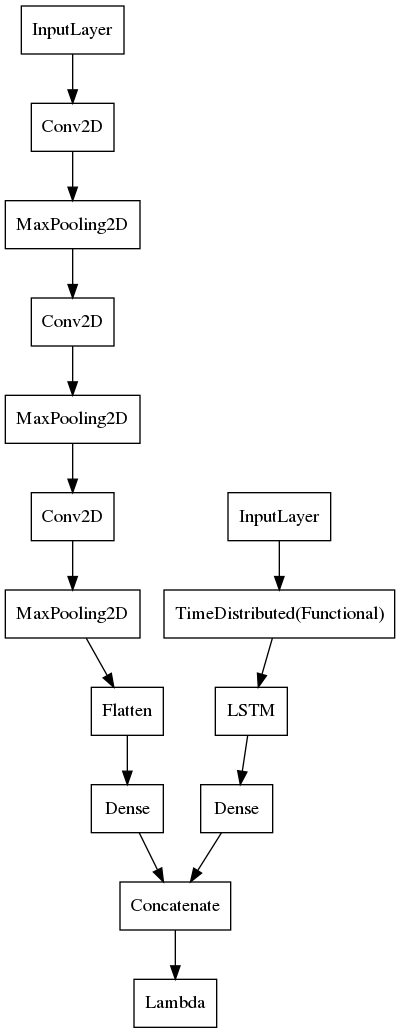
The first tower takes the (224,224,3) dimensional spectrogram and builds a simple ConvNet to process the image.
The second tower is essentially an lcrn, which allows for efficient parameter sharing in both space and time. It takes a sequence of video frames as input, feeding it to a tf.keras.layers.TimeDistributed wrapper of a pretrained ResNet50V2 CNN base. Finally, the sequence of image embeddings is fed into an LSTM layer for our video embedding.

We bring these signals together using tf.keras.layers.concatenate.
Like the movie poster similarity model, we found metric learning produced powerful embeddings. However, we found that a warmup epoch training a classifier using tf.keras.losses.SparseCategoricalCrossentropy loss helped speed up convergence in the final the phase using tfa.losses.TripletSemiHardLoss. It was also helped to train the model in phases, allowing progressively more trainable layers.
Results
Since this model produces high dimensional embeddings, we used approximate nearest neighbors to cluster similar trailers. The Annoy library makes it very fast to calculate the most similar trailers for any sample.
Here we show some of the better examples:
We can extract embeddings for commercials to match them to movies for seamless ad serving.

Conclusion
Comparing to scale of benchmark datasets used in recent research in Near Duplicate Video Retrieval (NDVR), we might first try to gather more sample videos.
To exploit the additional structure of movie trailers, we might scrape plot descriptions to introduce text embeddings for more precise recommendations.
We could also investigate cross-modal learning like these facebook researchers.
Or we could explore using attention mechanisms like ByteDance researchers did for NDVR.
Stay Tuned!