Check out the ros_neuralrecon repo here!
About a month ago, we remarked on some exciting modifications to NeuralRecon, which can generate dense scene reconstructions in real-time using TSDF fusion on posed monocular video.
Specifically, we noted that the image feature extraction could be shifted to the edge using depthai cameras after converting the MnasMulti backbone to .blob.
Trained on ScanNet, the researchers recommend custom data capture with ARKit using ios_logger. We found this works well if you have Xcode on a Mac and an iphone.
However, you will not find live feedback on the reconstruction since capture happens on an iphone while inference requires a GPU with at least 2GB RAM.
That’s why we are introducing ros_neuralrecon, which forks NeuralRecon and wraps the main class in a ROS node, packaging the demo to run live on devices like our turtlebot!
Our Path
Reviewing the way data samples are constructed, we find that our inferencing node requires a sequence of images as well as camera intrisic/extrinsic parameters.
We opt for a ROS-based implementation since ROS makes it easy to stream camera poses. We simply configure our node to subscribe to the /odom topic to parse this info.
Since our turtlebot uses depthai-ros to publish rgb images to the topic /rgb_publisher/color/image, we are all set to build the NeuralRecon ROS node.
At this point, we sample the images/poses by running rosbag record -a, recording into a ROS bag. This helps during testing/iteration on our inferencing node as we can simply run: rosbag play BAG_NAME.bag --loop for a steady stream of messages to consume.
ROS documentation shows how to make a simple publisher or subscriber and we want our node to do both. Furthermore, we want to synchronize images and camera poses, so we use a message_filter and a ROS node callback designed to process images and poses.
And so we can instantiate the main NeuralRecon class to run the model within a callback after parsing images and camera info to construct samples. Constructing a sample for NeuralRecon requires buffering a length 9 sequence of images and camera poses so we use deque(maxlen=9) in our ros node and test against its length before passing a sample for inference.
Formatting the samples requires some transforms and with small modifactions to the original repo, we can import these helpers. After parsing ROS messages, we transform and tensorize the sequences into a sample for inference.
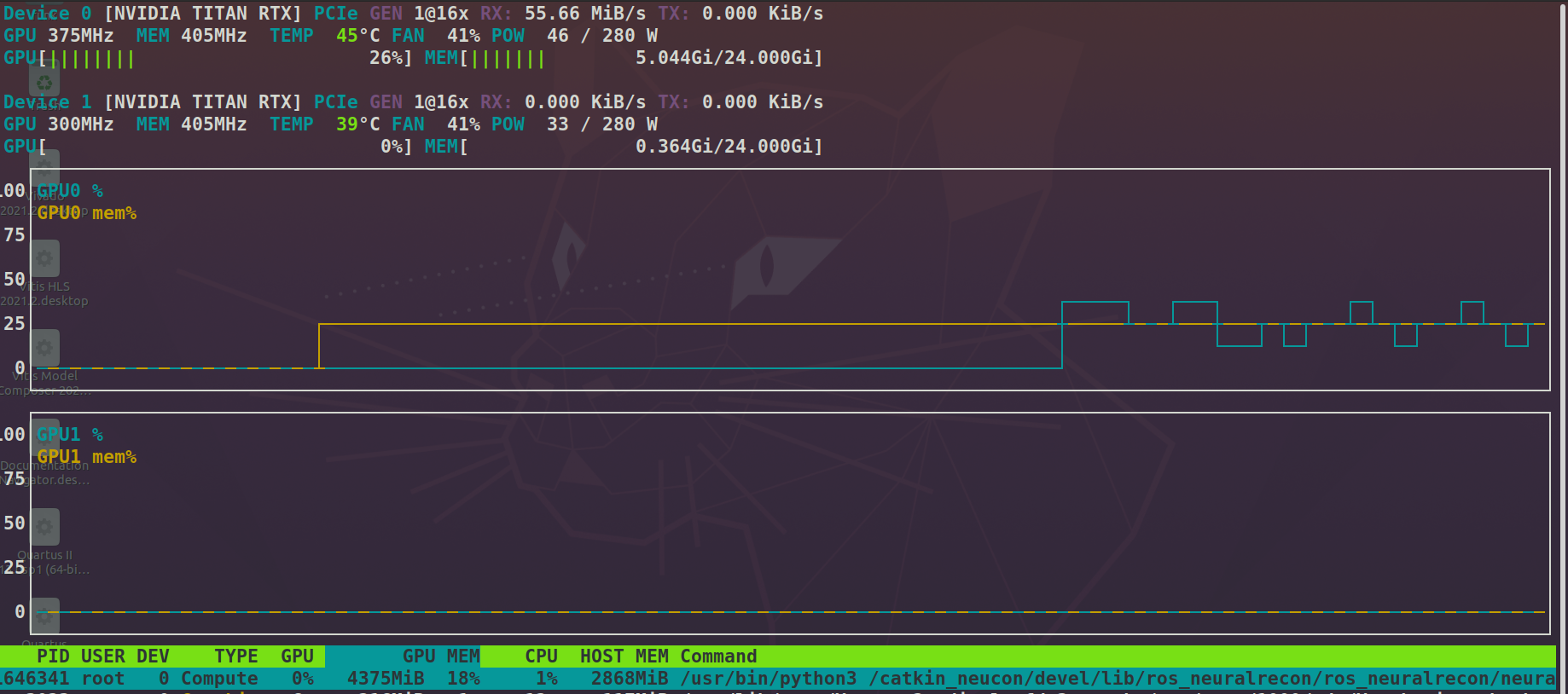
Monitoring nvtop, we find roughly 5GB memory utilization on a Titan RTX.
Next, we need to handle the inference results. Inspecting sample outputs, we find a dict with fields: ‘coords’ and ‘tsdf’ to signify the voxel positions and tsdf value with Nx4 and Nx1 tensors, respectively. Searching around, we found the SparseTSDF message similar to the data we wish to publish and so we add this message to ros_neuralrecon.

And so now we have a live recording method by re-packaging the repo with a ROS node wrapper!
Next, we want to move the MnasMulti feature extraction step onto our turtlebot’s oak-ffc. Doing so could mean our ros_neuralrecon node can be deployed on devices like a Jetson Nano with 4GB RAM. Additionally, by publishing image features as Float64MultiArray rather than rgb images, we can use less USB bandwidth.
After loading the torch model, we can use torch.onnx, openvino’s model optimizer, and blobconverter.
Unfortunately, here we hit a snag:
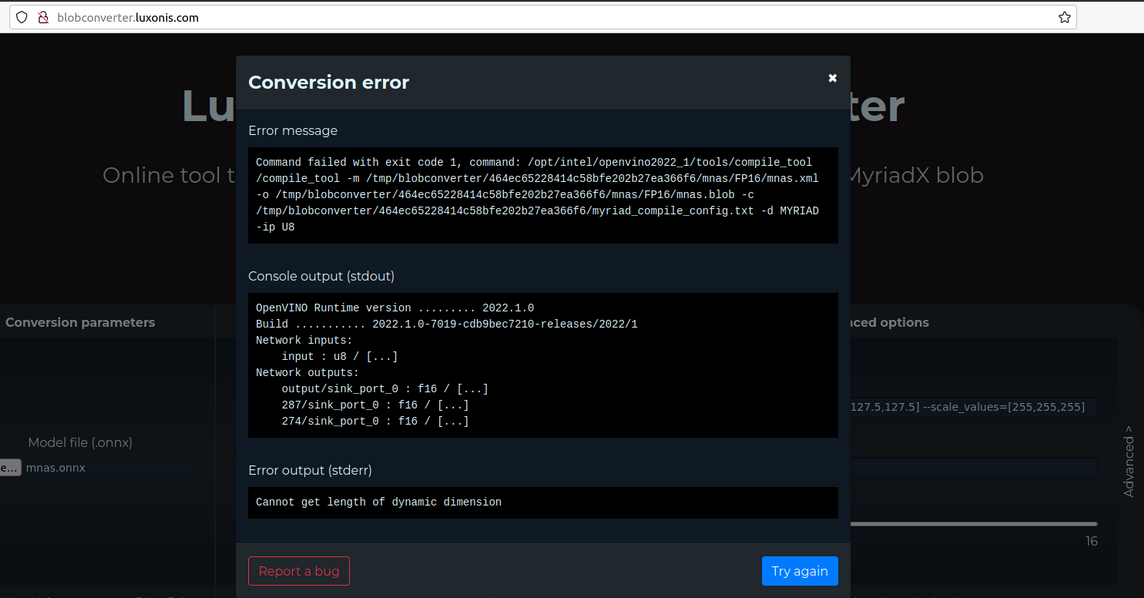
Now What?
Sometimes a model uses ops/layers not yet supported for the MyriadX VPU. It’s also possible that additional unknown parameters must be passed for successful conversion.
Retraining on ScanNet using a different backbone could be a workaround. In an insightful recent update to this line of work, other researchers recommend an EfficientNetv2 encoder along with greater use of geometric cues!
Naturally, we also want to support live visualization of our dense reconstruction. Here too, we have more work to do but hope you found our investigation interesting.
Stay tuned for updates!