Many recent successes in computer vision have been powered by the extension of BERTology beyond the mode of text-based data to image & video. Without a doubt, efficient Transformers which patchify input images a la ViT have initiated much of this progress. But in this post, we are interested in pretraining with self-supervised learning to develop compact representations we might use in various downstream tasks.
Datasets of real world interest often exhibit structures which are not exploited in research on benchmark datasets. Modeling around structures in the data, the ML practitioner can frame learning around auxiliary tasks with cheap supervisory signals. In practice, the robustness of deep learning to noisy labels makes this a reliable technique.
Indeed, we were surprised at the unreasonable effectiveness of coarse genre labels for developing representations for theatrical posters and applied fusion for a multi-modal extension to movie trailers.
But upon closer examination, we find much more structure in these human-generated compositions for human consumption. And in the case of content curated for humans, the cost of extracting more structure from an image corpus is relatively cheap.

We found openvino’s notebooks handy to quickly explore fast implementations of many models relevant to extracting more structure from our image corpus.

Our image corpus features layered compositions and these detection results can be leveraged to infer the title layer, but we can also use the text-based data to infer more information about the content with OCR.

Background segmentation offers another generally useful image processing technique we can use to analyze subjects in the foreground but our corpus provides especially challenging conditions we may need to work around.

With different perspectives, like monocular depth estimation, we can improve our estimation of saliency.

Depth information can even help reveal additional layers in the image compostions:

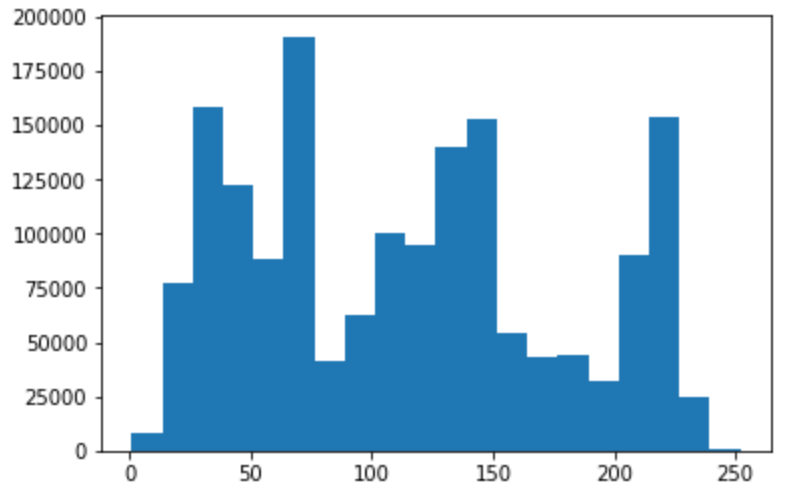
Looking for modes in the histogram of pixel intensities over the depth map, we might estimate 3 layers:
And after applying K-means (K=3), we find segmentations like:

Assuming we’ve performed OCR as above, simple heuristics guide our choice to label the green mask as the “Title Layer”. Trading off background segmentation with depth, and perhaps superpixel algorithms, we can focus additional analysis around the foreground subjects.
Simple featurizations of the foreground layer might include embeddings from image classifiers pre-trained on datasets like ImageNet or more structured pipelines using face or object detectors, perhaps with additional fine-tuning and even secondary models.
We’ve discussed numerous model-based inferences to acquire structured info about our image corpus. But sometimes, we can join additional sources like text or video data and attempt to fuse representations or apply cross-modal learning. PolyViT presents an exciting method of co-training a shared Transformer over multiple modalities of data.
After building up this rich structure, we can consider the different SSL tasks we can frame. SimSiam shows a simple approach using contrastive learning over pairs generated using alternative views of each image.
With layers and composition, as well as objects and text, we can frame all kinds of challenges for training. For example, we might consider the relationship between:
- patches from foreground/background layers
- salient objects among the foreground
- text/font and image semantics
Our annotations go beyond genre labels, allowing us to develop our own labeling scheme for curriculum learning. For example, we might augment labels with metadata encoding info like title placement.
Conclusion
Structured signals are all around us and the flexibility and improved accessibility of deep learning makes it cheap to experiment in developing representations.
As architecture search converges around the use of Transformers, the tasks used in pretraining with SSL and the way they are staged allow the practitioner to to instill inductive biases relevant to the data.