Factors like cheaper bandwidth and storage, expanded remote work, streaming entertainment, social media, robotics and autonomous vehicles, all contribute to the rapidly increasing volume of video data.
Nonetheless, performance in benchmark ML video tasks in perception, activity recognition, and video understanding lag behind the image counterpart.
In this post, we consider the challenges in applying ML to video while surveying some of the techniques en vogue to address them.
The Time Dimension
Treating video analytics as a search over space and time, the dimensionality begets additional hurdles to statistical and computational efficiency. Video inherits the HxWxD pixel grid from the image domain while extending dimensionality into the time dimension!
General video multimedia streams may feature multiple video or audio tracks. For our purposes, we consider video as a sequence of image frames sampled in time.

Each frame is associated with a timestamp at capture which imposes a natural sequential ordering of frames, often referenced by index. By probing, we find the average frame rate at which a multimedia container plays, measured by frames-per-second (fps ~ hertz).
Typically video is recorded at a resolution sufficient to smoothly resolve the position of a subject in time. This may afford the opportunity to eliminate computations of slowly-varying or uninteresting content without adversely impacting temporal consistency using simple strategies like skipping frames.
Motivated by results of Shannon, we recognize that complex and highly-variable video demands more samples in time to adequately characterize.
Spatial Dimensions
Computer vision tasks like segmentation benefit from higher spatial resolution input for fine-grained predictions. However, characterizing an image globally via classification typically utilizes lower frequency features like color and shape, hence can be efficiently computed over smaller images.
Analogously, spatial resolution requirements for video vary by application from high-fidelity cinematic or scientific content to low-resolution user-generated content optimized for serving.
For statistical and computational efficiency, spatial information can be coarsened from pixel level data since video features objects which are spatially similar in a local sense.
Geometric priors including shape and distance offer powerful signals to parse information from video. Using these spatial regularities we can pass to sparse, pointwise information while inferring global structure.
As with images, we frequently observe a center bias in the framing of subjects in video. Space reduction strategies range in simplicity from center cropping to introducing the context of saliency or key points. Even semantic object detection can be employed to specify regions of interest, localizing video for streamlined computations.
Localizing in Space
A module to identify and track object instances over time is important to characterize events in a video stream. Most tracking algorithms match objects to candidate region proposals over time by visual similarity or with a motion model.
![]()
In this databricks notebook, we implement a pyspark Transformers for face detection and tracking.
Localizing in Time
Object tracking heuristics can break down in complex, edited video sequences demanding additional processing to extract disjoint segments where these assumptions still hold. In a previous post we demo shot detection with Spark + FFmpeg.

For short and simple shots, sparsely sampling frames may suffice to represent the segment. We found this to be the case for modeling content-based video similarity models in prior experiments.
Offline v. Online Processing
For real-time applications, hardware-optimized implementations of simple models distributed closer to the source of capture can be performant. Search and anomaly detection tasks can use fast models to associate frames with a stream of annotation data.
Also user-generated content may be too voluminous to run complex inference workloads. Here fast, simple representation to index the catalogue can help.
Conversely, a slowly-growing corpus of curated cinematic content tends to present rich structure we can parse with additional modeling and analysis. Google offers a service to analyze and index metadata in video. Stanford researchers demonstrate vision pipelines for extracting structured information from video:
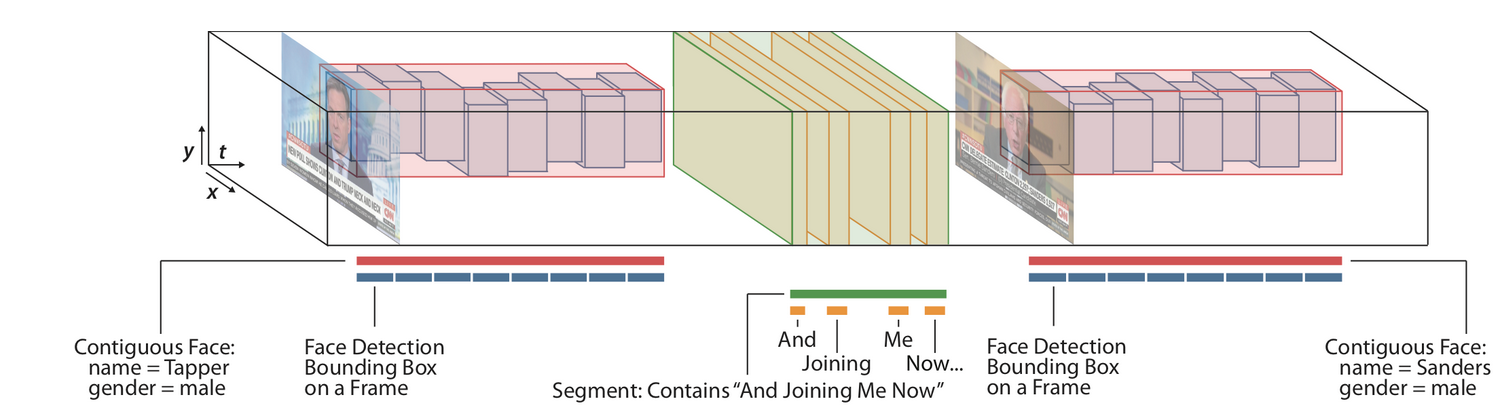
Pairing tools like Spark and FFmpeg, we can apply MapReduce to distribute processing the high-bandwidth sequential data. Here, we combine Spark with off-the-shelf face detectors, similar to the approach described above:
import face_recognition
boxes_schema = ArrayType(
StructType([
StructField("top", FloatType(), False),
StructField("right", FloatType(), False),
StructField("bottom", FloatType(), False),
StructField("left", FloatType(), False)
]))
def bbox_helper(bbox):
top, right, bottom, left = bbox
bbox = [top, left, bottom, right]
return list(map(lambda x: max(x, 0), bbox))
@udf(returnType=boxes_schema)
def face_detector(img_data, width=640, height=480, n_channels=3):
img = np.frombuffer(img_data, np.uint8).reshape(height, width, n_channels)
faces = face_recognition.face_locations(img)
return [f for f in faces]
@udf(returnType=ArrayType(DoubleType()))
def embedding_extract(img, bbox):
'''
SVM feature for recognition/identification
'''
box = bbox["detections"]
top, left, bottom, right = box.xmin, box.ymin, box.xmax, box.ymax
face_location = [tuple(map(int, (top, right, bottom, left)))]
return face_recognition.face_encodings(img.to_numpy(), known_face_locations=face_location)[0].tolist()
Video Datasets
Popular video datasets used to benchmark video understanding & activity recognition tasks, including UCF101, Kinetics, and YouTube8M.
Youtube Downloader is fantastic for fetching a few videos, but it can be challenging to download a large corpus from YouTube.
The Deepfake Detection Challenge, hosted by Kaggle, provides a corpus of video data for the binary classification task of identifying videos manipulated by Deepfake techniques.
ML Models on Video
During the DeepFake Detection Challenge, many participants sampled frames from short video segments and ensemble the results of an image classifier for prediction. Some considered LCRN models using temporal sequences of features extracted from image patches around the face.
Similarly, we’ve encoded motion using sequences of low-dimensional body key points for activity recognition with ActionAI.
This survey outlines research advances introducing temporal information through the two-stream networks using RGB and optical flow as input along with its modern incarnation in the neuro-inspired Slowfast architectures. The survey considers different approaches regarding time, including 3D convolution as well as the recent emphasis on making video inference more efficient.
Qualcomm researchers recently applied conditional computing to reduce work over space-time volumes by apply convolution to sparse residual frames while learning to skip frames with a gating mechanism. Naturally more time frames can help some predictions.
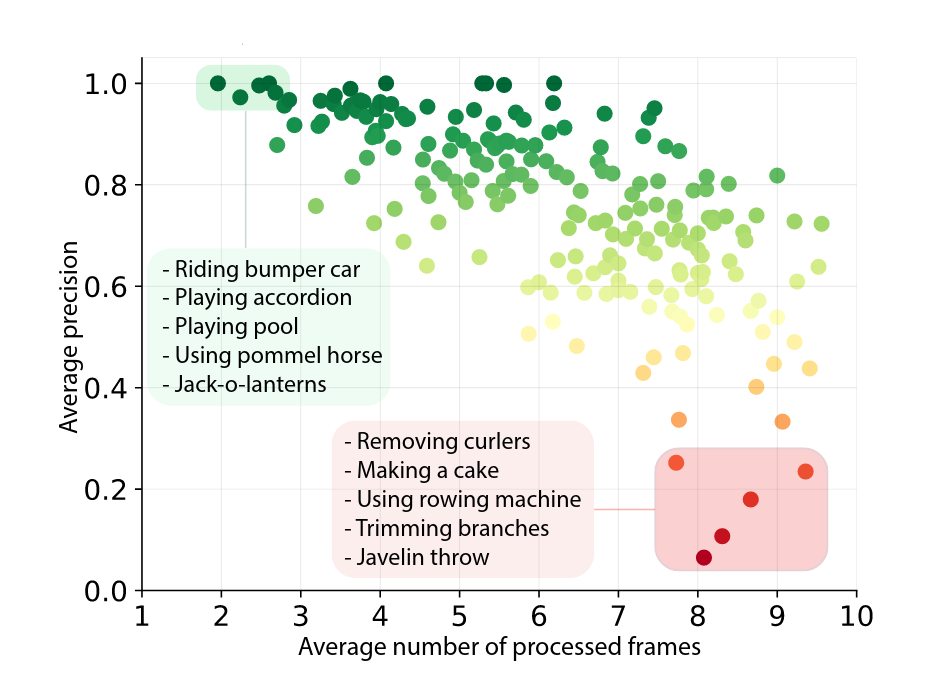
We are excited to apply ideas like these for content-aware video compression techniques.
Conclusion
Inferring structured information from video is challenging. Simply storing and accessing suitable training samples or learning specialized tools can limit the broader application of this technology.
Video understanding presses the limits in extracting structure from high-dimensional data. Success in this arena draws upon advances in hardware acceleration and signal processing.